
한글폰트 사용 가능한지 확인하기
먼저, 시각화 하기 위해서는 한글폰트가 그래프에서 잘 나오는지 확인해봐야 한다.
import pandas as pd
import matplotlib.pyplot as plt
plt.plot([1,2,3],[4,5,6]) #x축 눈금, ,y축 눈금
plt.title('그래프')
plt.show
영어로 나오면 나타나지만, 한글로 하면 이렇게 깨져서 나온다 #파이썬그래프한글깨짐
#그래프를 노트북 안에 그리기 위해 설정
%matplotlib inline
#패키지 라이브러리 가져오기
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
#그래프에서 마이너스 폰트 깨지는 문제에 대한 대처
mpl.rcParams['axes.unicode_minus']=False
#폰트지정하기
plt.rcParams['font.family']='NanumGothic'이 코드를 실행하고 다시 위에 코드를 실행하면 예쁘게 한글로된 title이 나타날 것이다.
데이터 수집하기
데이터셋은 서울시 공공자전가 대여이력 정보 데이터를 사용함 (2021 1월~6월)
https://data.seoul.go.kr/dataList/OA-15182/F/1/datasetView.do#
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
df1 = pd.read_csv('C:/Users/Owner/Downloads/공공자전거 대여이력 정보_2021.01.csv',encoding='cp949',low_memory=False)
df2 = pd.read_csv('C:/Users/Owner/Downloads/공공자전거 대여이력 정보_2021.02.csv',encoding='cp949',low_memory=False)
df3 = pd.read_csv('C:/Users/Owner/Downloads/공공자전거 대여이력 정보_2021.03.csv',encoding='cp949',low_memory=False)
df4 = pd.read_csv('C:/Users/Owner/Downloads/공공자전거 대여이력 정보_2021.04.csv',encoding='cp949',low_memory=False)
df5 = pd.read_csv('C:/Users/Owner/Downloads/공공자전거 대여이력 정보_2021.05.csv',encoding='cp949',low_memory=False)
df6 = pd.read_csv('C:/Users/Owner/Downloads/공공자전거 대여이력 정보_2021.06.csv',encoding='cp949',low_memory=False)
#low_memory=False 데이터 업로드 하다가 생긴 경고장 안보기데이터가 너무 많아서 시간이 오래걸림...
df1.head()
#concat
df = pd.concat([df1,df2,df3,df4,df5,df6])
#데이터 크기
df.shape #13613873건 데이터데이터가 개개개 많다
#데이터 메모리 사용-> 줄여야함
df.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 13613873 entries, 0 to 3445943
Data columns (total 11 columns):
# Column Dtype
--- ------ -----
0 자전거번호 object
1 대여일시 object
2 대여 대여소번호 int64
3 대여 대여소명 object
4 대여거치대 object
5 반납일시 object
6 반납대여소번호 object
7 반납대여소명 object
8 반납거치대 int64
9 이용시간 float64
10 이용거리 float64
dtypes: float64(2), int64(2), object(7)
memory usage: 1.2+ GB메모리용량이 1.2기가나 차지한다 이 메모리를 줄여야 한다..
데이터 전처리
#자전거번호, 값이 0인 대여거치대, 반납거치대 컬럼 제거
df.drop(columns= ['자전거번호','대여거치대','반납거치대'],inplace=True)
df.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 13613873 entries, 0 to 3445943
Data columns (total 8 columns):
# Column Dtype
--- ------ -----
0 대여일시 object
1 대여 대여소번호 int64
2 대여 대여소명 object
3 반납일시 object
4 반납대여소번호 object
5 반납대여소명 object
6 이용시간 float64
7 이용거리 float64
dtypes: float64(2), int64(1), object(5)
memory usage: 934.8+ MB934메가로 아까보다 줄였다. 분석에 필요하지 않는 컬럼이나 값이 다똑같은 것은 제거해버림
df['대여 대여소번호']=df['대여 대여소번호'].astype('category')
df['반납대여소번호']=df['반납대여소번호'].astype('category')고유번호를 category화 한다.
df.dtypes대여일시 object
대여 대여소번호 category
대여 대여소명 object
반납일시 object
반납대여소번호 category
반납대여소명 object
이용시간 float64
이용거리 float64
dtype: objectdf.info() #메모리가 줄음메모리 사용량이 779메가로 줄었다.
#datetime형으로 변경: 대여일시, 반납일시
df['대여일시']= pd.to_datetime(df['대여일시'])
df['반납일시']= pd.to_datetime(df['반납일시'],errors='coerce') #typeerror OutOfBoundsDatetime가 남 error가 있는 것은 null로 처리대여일시와 반납일시는 datetime형으로 변경해준다. 반납일시에서 OutOfBoundsDatetime type error가 나서 에러가 나는 부분은 null값 처리를 한다.
#결측치 확인
df.isnull().sum()대여일시 0
대여 대여소번호 0
대여 대여소명 0
반납일시 123
반납대여소번호 0
반납대여소명 0
이용시간 0
이용거리 269
dtype: int64결측치를 확인하고 결측치를 제거해준다.
#결측치 제거
df.dropna(inplace=True)#결측치 확인
df.isnull().sum()대여일시 0
대여 대여소번호 0
대여 대여소명 0
반납일시 0
반납대여소번호 0
반납대여소명 0
이용시간 0
이용거리 0
dtype: int64일별 이용현황 분석
대여 일시에서 날짜만 빼서 대여날짜 컬럼을 추가합니다.
df['대여날짜']= df['대여일시'].dt.date
df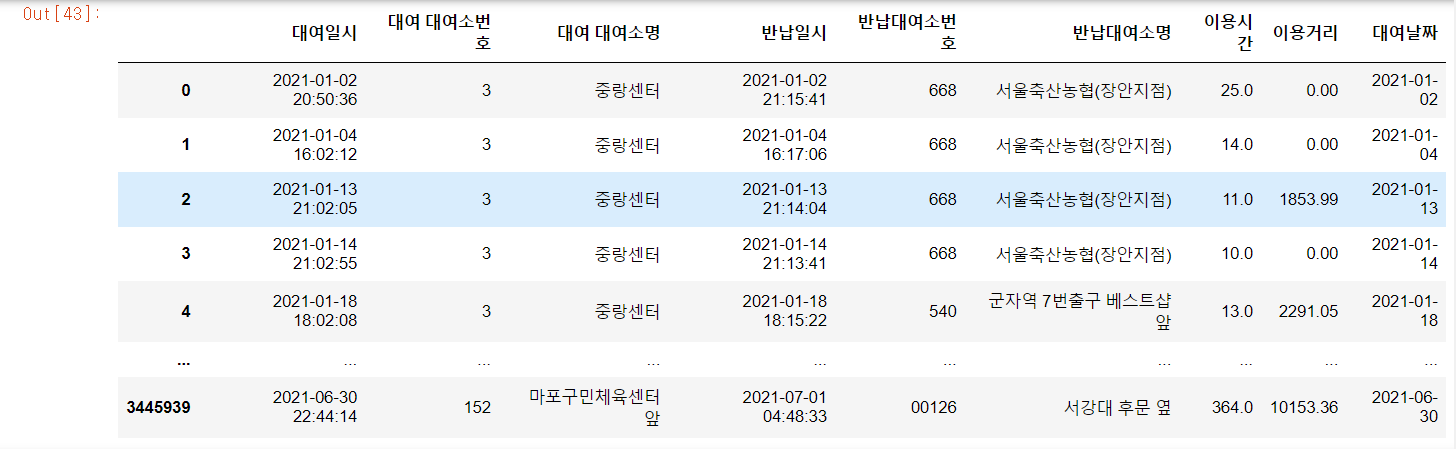
#대여날짜별 대여건수 추출
df_count = df.groupby('대여날짜').대여일시.count().to_frame() #대여일시별 대여날짜
#그룹바이한 컬럼이 index로 들어감#대여날짜 별대여건수 시각화
df_count.columns=['대여건수']
df_count
plt.plot(df_count.index,df_count.values) #x좌표 y좌표
plt.title('서울시 공공자전거 대여 날짜 별 대여건수')
plt.show()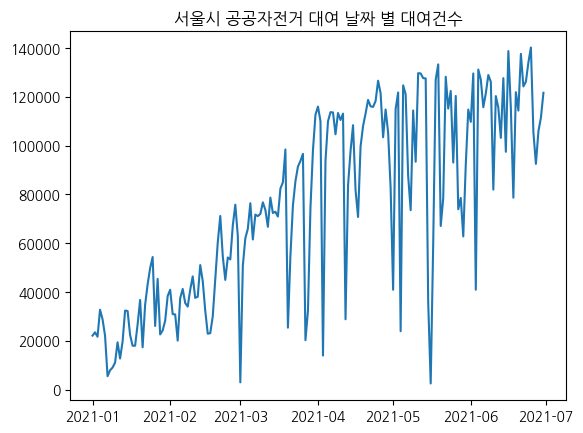
#대여날짜 별 이용시간의 합계
df_time = df.groupby('대여날짜')['이용시간'].sum().to_frame()#시각화
plt.plot(df_time.index,df_time['이용시간'])
plt.title('서울시 공공자전거 대여 날짜 별 이용시간')
plt.show()
#대여 날짜 별 이용거리 추출
df_distance= df.groupby('대여날짜')['이용거리'].sum().to_frame()#시각화
plt.plot(df_distance.index,df_distance['이용거리'])
plt.title('서울시 공공자전거 대여 날짜 별 이용거리')
plt.show()
#데이터프레임 합치기
df_date = pd.concat([df_time,df_distance,df_count],axis = 1)
df_date
시간대별 대여, 반납 현황
#대여시간, 반납시간 컬럼 추가
df['대여시간']=df['대여일시'].dt.hour
df['반납시간'] =df['반납일시'].dt.hour
df.head()
#시간대별 대여현황
s_rental = df['대여시간'].value_counts() #저녁시간때 대여건수가 많은 것을 알 수 있음
s_rental
대략 저녁시간이 많은 것을 알 수 있음.
#시간대별 반납현황
s_return=df['반납시간'].value_counts() #저녁시간대 반납이 많다
s_return
반납현황도 저녁시간이 많은 것을 알 수 있음.
#대여건수 시각화
s_rental = s_rental.sort_index() #시간대별 정렬
s_rental
x = s_rental.index
y = s_rental.values
plt.bar(x,y,color='skyblue')
plt.bar(x,y)
plt.title('서울시 공공자전거 시간대별 대여 건수')
plt.xlabel('대여시간')
plt.ylabel('대여건수')
plt.show()
그래프로 봐도 저녁시간에 몰린걸 알 수 있음
대여소별 대여/반납 현황
#대여 대여소번호 갯수
df['대여 대여소번호']0 3
1 3
2 3
3 3
4 3
...
3445939 152
3445940 152
3445941 152
3445942 2220
3445943 2220
Name: 대여 대여소번호, Length: 13613604, dtype: category
Categories (2493, int64): [3, 5, 10, 101, ..., 9999, 88888, 99997, 99999]#반납 대여소 번호 갯수
df['반납대여소번호']
#데이터 갯수 차이남. 반납대여소번호는 object이면서 00126임.즉 00126= 1260 668
1 668
2 668
3 668
4 540
...
3445939 00126
3445940 00437
3445941 00437
3445942 02526
3445943 02526
Name: 반납대여소번호, Length: 13613604, dtype: category
Categories (4811, object): [3, 10, 101, 102, ..., '화랑대역 2번출구 앞', '휘경sk뷰아파트 앞', '휘경여중고삼거리', '흑석역 4번출구']반납대여소와 대여 대여소랑 다른걸 알 수 있음. 반납대여소는 object으로 받아서 앞에 0이 뜸
즉 00488이랑 448이랑 다르게 간주한다는 것을 파악할 수 있움
df[df['반납대여소번호']=='00437']
df[df['대여 대여소번호']==437] #int형
대여대여소 번호는 int형 437 반납 대여소 번호는 00437로 나옴
반납 대여소 번호와 대여 대여소번호 형식과 똑같이 해주는 작업이 필요함.
#반납 대여소 번호 처리 (str형 변환)
df['반납대여소번호']= df['반납대여소번호'].astype('str')
#반납 대여소 번호 처리, 왼쪽 0 제거
df['반납대여소번호']=df['반납대여소번호'].str.lstrip('0')
#반납 대여소 번호 처리, int형 변환
df['반납대여소번호']=df['반납대여소번호'].astype('int')
#반납 대여소 번호 처리, 카테고리형 변환
df['반납대여소번호']=df['반납대여소번호'].astype('category')df['반납대여소번호']
이렇게 반납대여소 번호를 object에서 int로 수정했고, 앞에 00을 지우는 작업도함.
다음으로 대여건수와 반납건수가 가장 많읒 대여소를 구해봄
#대여건수가 가장 많은 대여소 best10
df[['대여 대여소번호','대여 대여소명']].value_counts()[:10].to_frame()

#반납건수가 가장 많은 대여소 best10].
df[['반납대여소번호','반납대여소명']].value_counts()[:10].to_frame()
대여와 반납 장소가 거의 일치함. 대여 장소 1순위인 여의나루역 1번출구 앞 대여소 이용현황을 구해보겠습니다
#여의나루역 1번출구 앞 대여소 이용현황
df_207=df[df['대여 대여소번호']==207]
df_207.head()
#반납 현황
df_207[['반납대여소번호','반납대여소명']].value_counts().to_frame()
#요일별 대여현황
import datetime
df_207['대여요일']= df_207['대여일시'].dt.strftime('%a')datetime 이용해서 대여요일 컬럼을 추가생성
df_207.head()
df_207['대여요일'].value_counts()Sun 14454
Sat 10932
Wed 10755
Fri 9191
Mon 8391
Thu 8037
Tue 7235
Name: 대여요일, dtype: int64
출처: 청년취업사관학교 sesac 서울시 공공데이터를 활용한 데이터 분석
'Python' 카테고리의 다른 글
| pytorch 이미지 모델링 II (1) | 2024.02.26 |
|---|---|
| pytorch 이미지 모델링 (0) | 2024.02.25 |
| pytorch 기본문법 II (1) | 2024.02.24 |
| pytorch 기본 문법 I (1) | 2024.02.24 |
| Window 11 python tensorflow gpu 설치 (1) | 2023.11.12 |