
출처: do it 자료구조와 함께 배우는 알고리즘 입문
선형 검색 알고리즘
직선 모양으로 늘어선 배열에서 원하는 키값을 가진 원소를 찾을 때까지 맨 앞부터 스캔하여 검색한다.
from typing import Any,Sequence
def seq_search(a: Sequence,key:Any) -> int:
#시퀀스에서 a에서 key와 값이 같은 원소를 선형 검색
i = 0
while True:
if i == len(a):
return -1 #검색에 실패하여 -1을 반환
if a[i]==key:
return i #검색에 성공하여 현재 검사한 배열의 인덱스를 반환
i +=1
if __name__ == '__main__':
num = int(input('원소 수를 입력하세요: ')) #num값을 입력받음
x = [None] *num #원소 수가 num인 배열을 생성
for i in range(num):
x[i] = int(input(f'x[{i}]: '))
ky = int(input('검색할 값을 입력하세요: ')) #검색할 키 ky를 입력받음
idx = seq_search(x,ky) #ky와 값이 같은 원소를 x에서 검색
if idx == -1:
print('검색값을 갖는 원소가 존재하지 않습니다')
else:
print(f'검색값을 x[{idx}]에 있습니다.')원소 수를 입력하세요: 7
x[0]: 6
x[1]: 4
x[2]: 3
x[3]: 2
x[4]: 1
x[5]: 2
x[6]: 7
검색할 값을 입력하세요: 1
검색값을 x[4]에 있습니다.
for문 이용한 코드
from typing import Any,Sequence
def seq_search(a:Sequence, key:Any) -> int:
#시퀀스 a에서 key와 값이 같은 원소를 선형검색
for i in range(len(a)):
if a[i]==key:
return i #검색 성공(인덱스 반환)
return -1 #(검색실패 -1 반환)
if __name__ == '__main__':
num = int(input('원소 수를 입력하세요: ')) #num값을 입력받음
x = [None] *num #원소 수가 num인 배열을 생성
for i in range(num):
x[i] = int(input(f'x[{i}]: '))
ky = int(input('검색할 값을 입력하세요: ')) #검색할 키 ky를 입력받음
idx = seq_search(x,ky) #ky와 값이 같은 원소를 x에서 검색
if idx == -1:
print('검색값을 갖는 원소가 존재하지 않습니다')
else:
print(f'검색값을 x[{idx}]에 있습니다.')seq_search 모델을 ssearch_while로 저장한 후 특정 인덱스를 검색해보았다
from ssearch_while import seq_search
t = (4,7,5.6,2,3.15,1)
s = 'string'
a = ['DTS','AAC','FLAC']
print(f'{t}에서 5.6의 인덱스는 {seq_search(t,5.6)}')
print(f'{s}에서 "n"의 인덱스는 {seq_search(s,"n")}')
print(f'{a}에서 DTS의 인덱스는 {seq_search(a,"DTS")}')(4, 7, 5.6, 2, 3.15, 1)에서 5.6의 인덱스는 2
string에서 "n"의 인덱스는 4
['DTS', 'AAC', 'FLAC']에서 DTS의 인덱스는 0
str형,float와 int형 문자가 섞인 배열에서 검색을 정확하게 수행
보초
검색에 실패했을 때, 가장 마지막 배열 끝에 키값을 저장한다.
만약 5를 검색하는데 a[0]~a[6]까지 해당값이 없으면 a[7]에 5를 저장한다.
선형 검색의 조건 (검색할 값을 찾지 못하고 배열의 맨 끝을 지나갔는지?)는 판단할 필요가 없
from typing import Any,Sequence
import copy
def seq_search(seq:Sequence, key:Any) -> int:
#시퀀스 a에서 key와 값이 같은 원소를 선형검색(보초법)
a = copy.deepcopy(seq) #seq복사
a.append(key) #보초key 추가
i = 0
while True:
if a[i] == key:
break
i += 1
return -1 if i == len(seq) else i #(검색실패 -1 반환),보초
if __name__ == '__main__':
num = int(input('원소 수를 입력하세요: ')) #num값을 입력받음
x = [None] *num #원소 수가 num인 배열을 생성
for i in range(num):
x[i] = int(input(f'x[{i}]: '))
ky = int(input('검색할 값을 입력하세요: ')) #검색할 키 ky를 입력받음
idx = seq_search(x,ky) #ky와 값이 같은 원소를 x에서 검색
if idx == -1:
print('검색값을 갖는 원소가 존재하지 않습니다')
else:
print(f'검색값을 x[{idx}]에 있습니다.')원소 수를 입력하세요: 7
x[0]: 6
x[1]: 4
x[2]: 3
x[3]: 2
x[4]: 1
x[5]: 2
x[6]: 8
검색할 값을 입력하세요: 2
검색값을 x[3]에 있습니다.
if i == len(a)가 성립하면 스캔 종료 -> 보초에서는 필요없으므로 삭제
if a[i]==key가 성립하면 스캔 종료
이진 검색
선형검색 보다 빠르게 검색할 수 있다는 장점이 있음. 오름차순이라 내림차순 배열에서 효율적인 검색이 가능하다
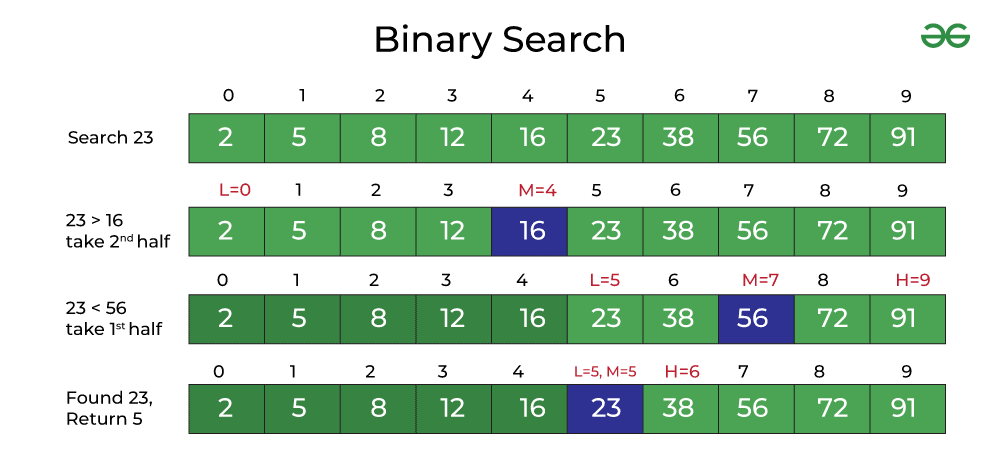
만약 23을 찾는다고 가정했을 때, 중앙에 위치한 원소를 기준으로 비교한다. 16보다 크므로 a[5]~a[9]까지 범위를 좁힌다. 좁힌 범위의 중앙 a[7]의 원소는 56이므로, 그 아래인 a[5]~a[6]에서 범위를 비교할 수 있다. 두 대상에서 23을 찾을 수 있다.
맨 앞 pl 은 0, 맨끝 pr 은 n-1은 중앙 pc (n-1)//2로 초기화 한다.
a[pc]<key 일 때 : 중앙보다 작은 배열값(a[p1]~a[pc])는 검색대상에서 제외한다. 검색 범위는 중앙 원소 a[pc+1]~a[pr]로 좁혀진다.
a[pc] > key 일 때 : a[pc]~a[pr]은 검색대상에서 제외하고 a[pl]~a[pc-1] 로 범위를 좁힌다.
이진검색 종료 조건:
- a[pc] == key일 경우
- 검색 범위가 더이상 없는경우
from typing import Any,Sequence
def bin_search(a:Sequence, key:Any) -> int:
pl= 0 #검색범위 맨앞
pr = len(a)-1 #검색 범위 맨 뒤
while True:
pc = (pl+pr) //2 #중앙원소의 인덱스
if a[pc] == key:
return pc #검색 성공
elif a[pc] < key:
pl = pc+1 #검색 범위를 뒤쪽 절반으로 좁힘
else:
pr = pc-1 #검색 범위를 앞쪽 절반으로 좁힘
if pl> pr:
break
return -1 #검색 실패
if __name__ == '__main__':
num = int(input('원소 수를 입력하세요: ')) #num값을 입력받음
x = [None] *num #원소 수가 num인 배열을 생성
print("배열 데이터를 오름차순으로 입력하세요")
x[0] = int(input('x[0]:'))
for i in range(1,num):
while True:
x[i]= int(input(f'x[{i}]:'))
if x[i] > x[i-1]: #바로 직전에 입력한 원솟값보다 큰값 입력
break
ky = int(input('검색할값 입력:')) #검색할 키값 ky를 입력
idx = bin_search(x,ky) #ky값과 같은 원소를 x에서 검색
if idx == -1:
print('검색값을 갖는원소가 존재하지 않음')
else:
print(f'검색값은 x[{idx}]')원소 수를 입력하세요: 7
배열 데이터를 오름차순으로 입력하세요
x[0]:1
x[1]:2
x[2]:3
x[3]:4
x[4]:5
x[5]:6
x[6]:7
검색할값 입력:5
검색값은 x[4]
검색 알고리즘은 반복할 때마다 범위가 거의 잘반으로 줄어드므로 검색하는데 필요한 비교횟수는 평균 logN번이고, 검색에 실패할경우 log(n+1)번, 검색에 성공할 경우 log(n-1)번이다.
복잡도
시간 복잡도: 실행하는데 필요한 시간 평가
공간 복잡도: 메모리와 파일공간이 얼마나 필요한지 평가
index() : 리스트 또는 튜플에서 검색 시 인덱스 함수로 수행할 수 있음. obj.index(x,i,j) 호출할 때 인수는 j또는 i,j를 생략할 수있음.
이진 검색의 시간 복잡도 알아보기
def bin_search(a:Sequence, key:Any) -> int:
pl= 0 #검색범위 맨앞 -1
pr = len(a)-1 #검색 범위 맨 뒤 -2
while True:
pc = (pl+pr) //2 #중앙원소의 인덱스-3
if a[pc] == key: #4
return pc #검색 성공 -5
elif a[pc] < key: #6
pl = pc+1 #검색 범위를 뒤쪽 절반으로 좁힘-7
else:
pr = pc-1 #검색 범위를 앞쪽 절반으로 좁힘-8
if pl> pr:#9
break
return -1 #검색 실패 -10
| 단계 | 실행 횟수 | 복잡도 |
| 1 | 1 | O(1) |
| 2 | 1 | O(1) |
| 3 | log n | O(log n) |
| 4 | log n | O(log n) |
| 5 | 1 | O(1) |
| 6 | log n | O(log n) |
| 7 | log n | O(log n) |
| 8 | log n | O(log n) |
| 9 | log n | O(log n) |
| 10 | 1 | O(1) |
복잡도를 모두 더하면 O(log n)이 도출된다. O(n)과 O(log n)은 O(1)보다 더 크다. 수가 클수록 알고리즘 실행 시간이 길어진다.
해시법
'데이터 저장 위치 = 인덱스'를 간단한 연산으로 구함. 이 방법은 추가 삭제도 효율적으로 할 수 있음.
원소값을 원소갯수로 나눈 나머지를 해시값이라고 한다. 키를 해시값으로 변환하는 과정을 해시함수 라고 한다.
| 키 | 5 | 6 | 14 | 20 | 29 | 34 | 37 | 51 | 69 | 75 |
| 해시값(13으로 나눈 나머지) | 5 | 6 | 1 | 7 | 3 | 8 | 11 | 12 | 4 | 10 |
만약 18을 추가하려고 할때, 13으로 나눈 나머지는 5이므로 x[5]에 대입하면 되지만 이미 값이 들어 있다. 이와같이 키와 해시값은 (n:1)이기 때문에 저장할 버킷이 중복되는 현상을 해시충돌이라고 한다.
해시충돌이 발생할 경우 체인법(해시값이 같은 원소를 연결 리스트로 관리), 오픈 주소법(빈 버킷을 찾을 때까지 해시 반복)으로 해결한다.

해시값이 같은 데이터를 연결리스트에 의해 체인모양으로 연결한다. table[4]는 버킷 69를 참조하고, 69의 뒤쪽 포인터가 17를 참조하고, 버킷17의 뒤쪽 포인터는 뒤쪽 노드가 존재하지 않음을 알려주는 None이다.
체인법으로 해시함수 구
from __future__ import annotations
from typing import Any,Type
import hashlib
class Node:
def __init__(self,key:Any,value:Any,next:Node)-> None:
self.key = key #키(임의의 자료형)
self.value = value #값(임의의 자료형)
self.next = next #뒤쪽 노드를 참조(Node형)chainedhash 해시 클래스 만들기
class ChainedHash:
def __init__(self,capacity:int)-> None: #함수초기화
#초기화
self.capacity = capacity #해시 테이블 크기 지정
self.table = [None]* self.capacity #해시 테이블(리스트) 선언
def hash_value(self,key:Any) -> int:
if isinstance(key,int):
return key % self.capacity
return(int(haslib.sha256(str(key).encode()).hexdigest(),16) % self.capacity)capacity : 해시 테이블의 크기(배열 table의 원소수)를 나타냄
table: 해시 테이블을 저장하는 list형 배열을 나타냄
해시 테이블을 크게 만들면 충돌 발생을 억제할 수 있지만 메모리를 낭비함. 충돌을 피하려면 해시 함수가 해시 테이블 크기보다 작거나 같은 정수를 고르게 생성해야함.
key가 int인 경우: key를 해시크기로 나눈 나머지를 해시값으로함
key가 int형이 아닌경우 : 문자열, 리스트, 클래스형 같은 값으로 바로 나눌 수 없음. 표준 라이브러리형으로 변환이 필요함
위의 코드에서 사용한 표준 라이브러리
sha256 알고리즘: 주어진 바이트 문자열의 해시값을 구하는 해시 알고리즘의 생성자
encode() 함수: hashlib.sha256에는 바이트 문자열의 인수를 전달해야함. key를 str형 문자열로 변환한 뒤 그 문자열을 encode에 전달하여 바이트 문자열 생성
hexdigest(): sha256알고리즘에서 해시값을 16진수 문자열로 꺼냄
int() : hexdigest 함수로 꺼낸 문자열을 16진수 문자열로 하는 int형으로 변환