
최적화(optimization) 이란 loss function의 값을 낮추는 매개변수의 최적값을 찾는 과정이다
확률적 경사 하강법(SGD)-> 매개변수의 기울기를 구하여 기울어진 방향으로 매개변수값 갱신
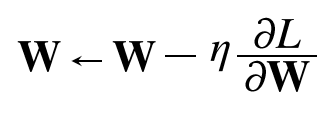
W: 갱신할 가중치 매개변수
∂L/ ∂W: W에 대한 손실 함수의 기울기
η: learning rate(0.01또는 0.001)
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):#딕셔너리 형태의 변수
for key in params.keys():
params[key] -= self.lr * grads[key]update 메서드 SGD과정에서 반복함. params['W1'], grads['W1'] 와 같이 가중치 매개변수와 기울기 저장
SGD의 단점이 있다면 최적화 갱신 경로가 비효율적 -> 이러한 단점을 해결해주는 것이 모멘텀, AdaGrad,Adam이 있음
모멘텀
모멘텀은 운동량을 의미하며, 물리학과 관계가 있

v: velocity 속도를 의미
av: 물체가 아무런 힘을 받지 않았을 때 서서히 하강시키는 역할
class Momentum:
def __init__(self, lr=0.01, momentum = 0.9):
self.lr = lr
self.momentum = momentum
self.v = None #초기화 때는 아무것도 담지 않음
def update(self, params, grads):
if self.v is None:
self.v = {} #딕셔너리 변수로 저장
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
params[key] += self.v[key]
모멘텀은 SGD에 비해 최적화 갱신경로의 지그재그 정도가 덜함. x축 방향으로 빠르게 다가가 지그재그 움직임이 줄어듦
AdaGrad
학습률을 적절히 설정해야 학습이 잘 이루어짐.
학습률 감소 -> 학습률을 효과적으로 정함. 학습을 진행하면서 학습률을 점차 줄임
AdaGrad -> 전체의 학습률 값을 각각의 매개변수에 맞게 일괄적으로 낮춤

h -> 기존 기울기 값을 제곱하여 계속 더해줌 (첫번째줄 동그라미는 행렬의 원소별 곱셈)
매개변수 갱신시 1/√h 를 곱해 학습률 조정
class AdaGrad:
def __init__(self, lr = 0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += gards[key] * gards[key]
params[key] -= self.lr * grads[key]/(np.sqrt(self.h[key])+1e-7)
#0이 담겨 있어도 0으로 나누는 사태를 막아줌AdaGrad의 최적화 갱신 경로는 최솟값을 향해 효율적으로 움직임. 갱신강도가 약해지고, 지그재그 움직임이 줄어든다
Adam
모멘텀+ AdaGrad 의 융합
하이퍼파라미터의 편향 보전이 진행된다는 점이 특징이다.
class Adam:
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
#m(1차 모멘트, 즉 이동 평균)와 v(2차 모멘트, 즉 이동 분산)을 None으로 초기화
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val) #파라미터와 동일한 차원을 가진 0 벡터로 초기화
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter)
for key in params.keys():
#self.m[key] = self.beta1*self.m[key] + (1-self.beta1)*grads[key]
#self.v[key] = self.beta2*self.v[key] + (1-self.beta2)*(grads[key]**2)
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key]) #현재 그래디언트와 이전 스텝의 m을 이용하여 m을 업데이트
self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])#현재 그래디언트의 제곱과 이전 스텝의 v를 이용하여 v를 업데이트
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
#unbias_m += (1 - self.beta1) * (grads[key] - self.m[key]) # correct bias
#unbisa_b += (1 - self.beta2) * (grads[key]*grads[key] - self.v[key]) # correct bias
#params[key] += self.lr * unbias_m / (np.sqrt(unbisa_b) + 1e-7)#v의 제곱근에 작은 수를 더하는 이유는 0으로 나누는 것을 방지하기 위함
어떤것을 채택해야 하는가?
MNIST 데이터셋으로 비교했을때, loss function 값이 AdaGrad,Adam, Momentum, SGD 순으로 좋게 나왔다.
데이터 마다 loss function이 최소로 나오는 매개 변수 갱신방법은 다르기 때문에 직접 해봐야한다
'Deep Learning > from scratch I' 카테고리의 다른 글
| [밑바닥부터 시작하는 딥러닝 - 7장 합성곱 신경망(CNN) I] (1) | 2024.02.10 |
|---|---|
| [밑바닥부터 시작하는 딥러닝 - 6장 학습 관련 기술들 II] (1) | 2024.02.09 |
| [밑바닥부터 시작하는 딥러닝 - 5장 오차역전파법 II] (1) | 2024.02.08 |
| [밑바닥부터 시작하는 딥러닝 - 5장 오차역전파법 I] (0) | 2024.02.08 |
| 밑바닥부터 시작하는 딥러닝 - 4장 신경망 학습 II] (0) | 2024.02.07 |