
손실함수(loss function)
1. 오차제곱합

yk -> 신경망의 출력값
tk -> 정답 레이블
k -> 데이터의 차원수
출력값에서 정답레이블의 차를 구한 후, 이의 제곱합을 구한 후 2로 나눠준다.
def sum_squares_error(y,t):
return 0.5 * np.sum((y-t)**2)import numpy as np
t = [0,0,1,0,0,0,0,0,0,0] # 원핫인코딩으로 나타낸 정답 레이블
#1
y = [0.1,0.05,0.6,0.0,0.05,0.1,0.0,0.1,0.0,0.0] # 출력값
print(sum_squares_error(np.array(y),np.array(t)))
#2
y = [0.1,0.05,0.1,0.0,0.05,0.1,0.0,0.6,0.0,0.0] # 출력값
print(sum_squares_error(np.array(y),np.array(t)))0.09750000000000003
0.5975
첫번째 값의 sse가 더 작아서 정답에 더 가깝다.
2. 교차 엔트로피 오차
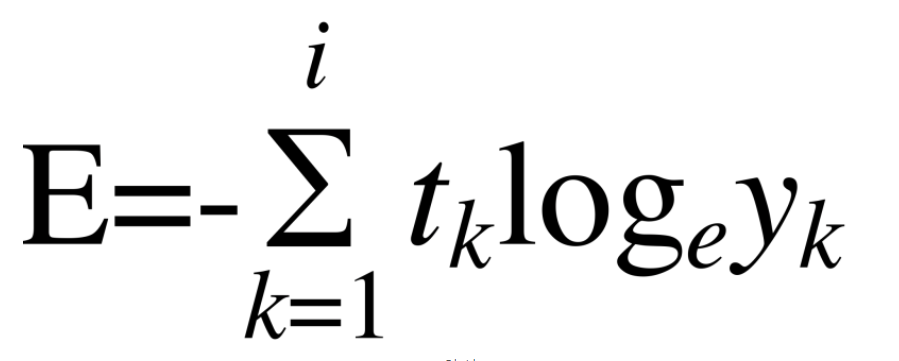
만약 정답레이블이 2고 신경망 출력이 0.6이라면 -log0.6= 0.51 과 같이 나타낸다.
교차 엔트로피 오차는 정답일 때의 출력이 전체 값을 정하게 된다.
y = logx는 x가 1일 때 y=0이 된다. x가 작아질수록 y도 작아진다.
def cross_entropy_error(y,t):
delta = 1e-7
return -np.sum(t*np.log(y+delta))log 함수에 0을 입력하면 -inf 가 나오기 때문에 아주작은 값을 더해서 -inf가 되는것을 방지함
y = [0.1,0.05,0.6,0.0,0.05,0.1,0.0,0.1,0.0,0.0] # 출력값
print(cross_entropy_error(np.array(y),np.array(t)))
y = [0.1,0.05,0.1,0.0,0.05,0.1,0.0,0.6,0.0,0.0] # 출력값
print(cross_entropy_error(np.array(y),np.array(t)))0.510825457099338
2.302584092994546
오차값이 더 적은 첫번째 추정이 정답일 가능성이 높음
평균손실함수
train 모든 데이터에 대한 손실함수의 합 구하기

손실함수를 N개의 데이터로 확장, 마지막에 N으로 나누어 정규화함.
미니배치 학습
미니 배치 학습이란 전체 데이터의 일부를 추려 학습을 수행하는 것을 의미함
MNIST 데이터로 미니배치학습을 위한 데이터를 무작위로 선정할때, 다음과 같이 코드구현함
import sys,os
sys.path.append(os.pardir)
import numpy as np
(x_train,t_train),(x_test,t_test)= load_mnist(flatten= True, normalize=False,one_hot_label=False)
print(x_train.shape) #(60000,784)
print(t_train.shape) #(60000,10)
train_size = x_train.shape[0]
batch_size= 10
batch_mask = np.random.choice(train_size,batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]무작위로 10개의 인덱스를 가져옴
미니배치 교차 엔트로피 오차 구현
def cross_entropy_error(y,t):
if y.ndim==1:
t= t.reshape(1,t.size) # 1*n으로 바꿔줌
y= y.reshape(1,y.size)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size),t]+1e-7)) /batch_size #배치의 크기로 나줘 정규화, 한장당 평균의 교차 엔트로피 오차 계산
만약 batch_size가 5이면 np.arange(batch_size)는 [0,1,2,3,4] 라는 넘파이 배열 생성, t에는 레이블이 [2,7,0,9,4]로 저장되어 있으면 y[np.arange(batch_size),t]는 [y[0,2],y[1,7],y[2,0]...] 과 같이 numpy array 생성
손실함수를 설정하는 이유?
만약 정확도를 지표로 삼으면, 계단함수로 했을 때, 기울기를 미분하면 모두 0으로 나온다. 미분값이 0이면 가중치 매개변수를 어느쪽으로 움직여도 loss function은 줄어들지 않음.
미분
편미분
변수가 여럿인 함수에 대한 미분
x0=3, x1=4 일때, x0에 대한 편미분
def numerical_diff(f,x):
h = 1e-4 #0.0001
return (f(x+h)-f(x-h))/(2*h) # 수치미분의 오차를 줄이기 위해 (x+h)와 (x-h) 일때의 함수 f의 차분을 계산
def function_tmp1(x0):
return x0*x0 + 4.0 **2.0
numerical_diff(function_tmp1,3.0)6.00000000000378x0=3, x1=4 일때, x1에 대한 편미분
def function_tmp2(x1):
return 3.0**2.0 + x1*x17.999999999999119
경사하강법
변수의 편미분으로 정리한 것을 기울기라고함
경사하강법은 현위치에서 기울여진 방향으로 움직임. 이렇게 해서 함수의 값을 줄이는 것이 경사법이다.
최적의 매개변수 값을 찾아야 하는데 , 이 때 최적은 손실함수가 최솟값이 될 때의 매개변수값이다
기울기를 이용해서 함수의 최솟값을 찾아야한다.

인풋 - 학습률 * 아웃풋 미분값을 해주어 매개변수값을 갱신해준다. 보통 학습률은 0.01이나 0.001 과 같은 특정값을 설정함.
def gradient_descent(f,init_x,lr=0.01,step_num=100):
x= init_x
for i in range(step_num):
grad= numerical_gradient(f,x)
x -= lr*grad
return xinit_x는 초기값, lr은 학습률, step_num은 경사법에 따른 반복횟수를 의미한다.
함수의 기울기는 numerical_gradient(f,x)로 구하고, 기울기에 학습률을 곱하여 step_num번 동안 갱신한다.
경사법으로 f(x0,x1)= x0^2 + x1^2의 최솟값을 구해라
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x)
for idx in range(x.size):
tmp_val = x[idx]
# f(x+h) 계산
x[idx] = tmp_val + h
fxh1 = f(x)
# f(x-h) 계산
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 값 복원
return gradimport numpy as np
def function_2(x):
return x[0]**2 + x[1]**2
init_x = np.array([-3.0,4.0])
gradient_descent(function_2,init_x=init_x,lr=0.1,step_num=100)array([-6.11110793e-10, 8.14814391e-10])거의 (0,0)과 근사하므로 정확한 결과를 얻은것이다. learning rate가 너무 크거나 작으면 큰값으로 발산해버린다.
학습률을 적절히 설정하는 것이 중요하다
신경망에서의 기울기
import sys,os
sys.path.append(os.pardir)
import numpy as np
from common.functions import softmax,cross_entropy_error #앞서 정의한 메소드
from common.gradient import numerical_gradient
class simpleNet:
def __init__(self):
self.W = np.random.randon(2,3) #정규분포 초기화, 2*3 가중치 매개변수 하나를 인스턴스 변수로 갖는다
def predict(self,x):
return np.dot(x,self.W)
def loss(self,x,t):
z= self.predict(x)
y = softmax(z)
loss = cross_entropy_error(y,t)x는 input data, t는 정답레이블
net = simpleNet()
print(net.W) #가중치 매개변수
[[0.47355232, 0.9977393 , 0.84668094],
[0.85557411, 0.03563661, 0.69422093]]
x= np.array([0.6,0.9])
p = net.predict(x)
print(p)
#[1.05414809 0.63071653 1.1328074]
np.argmax(p) #최댓값의 인덱스
#2
t= np.array([0,0,1]) #정답레이블
net.loss(x,t)
#0.92806853
def f(W):
return net.loss(x,t)
d(W)= numerical_gradient(f,net.W)
print(dW)[[0.21924763, 0.14356247 , -0.36281009],
[0.32887144, 0.2153437, -0.54421514]]
numerical_gradient(f,x)의 인수 f는 함수, x는 함수 f의 인수이다. 여기서 net.W를 인수로 받아 손실함수를 계산하는 f를 정의함.
∂L / ∂ w11은 대략 0.2이다. 이는 w11은 h만큼 늘리면 손실함수의 값은 0.2h만큼 증가한다는 의미이다. ∂L / ∂ w23은 h만큼 늘리면 0.5h 만큼 감소한다. w11은 음의방향으로 갱신하고, w23은 양의 방향으로 갱신해야 손실함수를 줄일 수 있다. 갱신되는 양에는 ∂L / ∂ w23이 w11보다 크게 기여한다.
'Deep Learning > from scratch I' 카테고리의 다른 글
| [밑바닥부터 시작하는 딥러닝 - 5장 오차역전파법 II] (1) | 2024.02.08 |
|---|---|
| [밑바닥부터 시작하는 딥러닝 - 5장 오차역전파법 I] (0) | 2024.02.08 |
| 밑바닥부터 시작하는 딥러닝 - 4장 신경망 학습 II] (0) | 2024.02.07 |
| [밑바닥부터 시작하는 딥러닝 - 3장 신경망] (1) | 2024.02.05 |
| [밑바닥부터 시작하는 딥러닝 - 2장 퍼셉트론] (0) | 2024.02.05 |