
1. 실행계획에서 index 사용 여부 확인하기
MS SQL에서 쿼리 > 실제 실행 계획 포함 클릭

실제 실행계획 포함 후, 아래 쿼리문 실행함.
위의 Set statistics io on 문은 어느정도의 읽기 IO가 발생됐는지 알 수 있다.
SET STATISTICS IO ON;
SELECT s.SupplierID, p.ProductID, p.ProductName, p.UnitPrice
FROM dbo.Suppliers AS s INNER JOIN dbo.Products AS p
ON s.SupplierID = p.SupplierID
WHERE p.SupplierID = 2메시지 창을 보면 아래와 같이 나오는데, lab 논리적 읽기 숫자확인을 봐야한다.
숫자는 쿼리에서 읽은 [data/index] page 수 의 계산으로 도출된다. 숫자가 클수록 데이터를 많이 참고했다는 뜻!
숫자가 0이면 테이블이나 인덱스를 읽을 때 메모리(버퍼 캐시)에서 데이터 페이지를 전혀 읽지 않았다는 의미이다.
즉, 인덱스를 매우 효율적으로 사용했다는 의미다. 특히 WHERE SupplierID = 2 조건에서 인덱스를 통해 바로 찾아갔기 때문에, 테이블을 full scan하지 않고 인덱스를 통해 필요한 데이터만 정확하게 찾아갔다는 뜻이라고 할 수 있다.

실행 계획은 아래와 같이 뜬다. 인덱스를 사용하는 경우인 것을 확인가능하다.

인덱스를 정상적으로 사용하지 못하는 경우, Clustered Index Scan, 인덱스 스캔(NoneClustered) 과 같이 뜬다.
2. 개발 및 관리 도구 사용 주의
1) SSMS Intellisense 사용 과정에서, 잠금, 차단과 같은 이슈가 발생할 수 있음. 특히 운영서버에서 주의할 것
사용한다면 개발 DB에서만 사용할 것.
- SSMS Intellisense란? 코드 자동 완성 및 구문 도움말 기능을 의미. 구문검사 및 자동완성 도움
2) SQL Server Profiler 잘못 사용하면 서버에 큰 부하줌. 권한 관리를 통해 사용 제약 필요.
도구> 옵션> 텍스트 편집기> Transact-SQL<IntelliSense 해제 (운영서버에서 해제할것)

3. WHERE 절과 JOIN 절 작성 순서
where 절 조건식의 순서 -> 쿼리 성능에 영향을 미칠까 ? 순서대로 처리되는걸까?
교환법칙을 생각해보자.
A+B = B+A
A*B = B*A
순서가 어떻든 값은 같다는 것이다.
Query Optimizer : 쿼리를 실행할 때 가장 효율적인 실행 계획을 찾아주는 데이터베이스 엔진의 핵심 구성 요소
SELECT * FROM Orders o
JOIN Customers c ON o.CustomerID = c.CustomerID
WHERE o.OrderDate > '2023-01-01'위와 같은 쿼리가 있을 때, Orders 테이블을 먼저 읽을지, Customers를 먼저 읽을지, 인덱스를 사용할지 테이블 스캔을 할지, 어떤 조인 방식을 사용할지 최적으로 자동으로 수행. 교환법칙, 결합법칙 내용도 포함.
where 절 작성시, 개발이나 유지보수 측면에서 의미있는 순서를 찾아 사용해야함.
1) 교환법칙
--1)
SELECT *
FROM dbo.[Order Details]
WHERE (Discount <> 0)
AND (10 / Discount >= 0)
--2)
SELECT *
FROM dbo.[Order Details]
WHERE (10 / Discount >= 0)
AND (Discount <> 0)1번과 2번식은 where절의 순서가 바뀌었다.
10 / Discount >= 0의 절을 보면, 만약 discount가 0일 때 10/0 은 수학적으로 정의될 수 없는 연산이 나온다.
하지만 1)과 2) 를 실행했을 때, 둘다 838행으로 같은 값이 나온다.
즉, 2)번 식에서 query optimizer가 자동으로 순서를 바꿔 실행해주었다는 의미이다.
2)번 식의 실행계획을 보면, 조건자에서 discount <>0을 먼저 실행했다는 것을 알 수 있다.

1)
SELECT *
FROM dbo.Orders AS o
INNER JOIN dbo.[Order Details] AS d
ON o.OrderID = d.OrderID
WHERE o.OrderID = 10249
2)
SELECT *
FROM dbo.[Order Details] AS d
INNER JOIN dbo.Orders AS o
ON d.OrderID = o.OrderID
WHERE d.OrderID = 10249outer join은 inner join과 달리 순서에 따라서 결과에 영향을 미친다.
inner join 일때만 최적화가 기능한다.
4. 날짜시간 상수 이해, char, varchar 차이점
1) 날짜 입력시 : 1999-02-27
2) 시간만 입력시 : 1900-01-01 12:37 ( 1900-01-01 default로 들어감)
3) getdate() + 1 : 더하기 뺴기는 일자를 기준으로 한 연산
4) 20230227 23:59:59.999 -> 끝자리가 998까지는(997로 반올림됨) 20230227이나, 999는 20230228 0시0분 0초로 넘어감
SELECT
CAST('20230227 23:59:59.997' AS DATETIME) -- -> 2023-02-27 23:59:59.997
CAST('20230227 23:59:59.998' AS DATETIME) -- -> 2023-02-27 23:59:59.997
CAST('20230227 23:59:59.999' AS DATETIME) -- -> 2023-02-28 00:00:00.000
날짜 함수에 대해 convert 함수 이용 시 성능에 문제가 생길 수도 있음.
5) 공백처리
'문자 ' 와 같이 오른쪽에 후행 공백이 있을 때 RTRIM 함수를 써서 공백을 제거함
왼쪽 공백은 LTRIM 사용함.
WHERE varchar_col = RTRIM(@char)안에 subquery 또는 like 와 같은 문자 패턴매칭을 하는 문장 있을 때, RTRIM 함수가 성능에 안좋은 영향을 미칠 수도 있다.
검색 조건에서 비교 연산을 할 때는 오른쪽 후행 공백을 할 필요가 없기 때문에 RTRIM 함수를 사용하지 않아도 된다.
DECLARE @varchar varchar(8), @char char(8)
SELECT @varchar = 'sql ', @char = 'sql '
IF ( @varchar = 'sql' )
PRINT '같다'
IF ( @char = 'sql' )
PRINT '같다'
IF ( @varchar = @char )
PRINT '같다'select 문장을 보면, 가변길이 문자열 varchar이나 고정길이 문자열 char둘 다 오른쪽 후행공백이 있다.
if문 3개를 동시에 실행했을 때, 다음과 같이 출력된다.

그러므로 비교연산시 후행공백 제거 RTRIM을 쓰지 않아도 된다.
6) 조건절 사용시 괄호 주의
WHERE
((CategoryID = 1 OR CategoryID = 2)
AND UnitPrice > 20
OR (SupplierID = 1 OR SupplierID = 3 OR SupplierID = 5)
AND Discontinued = 0)
OR (UnitsInStock > 0 OR UnitsOnOrder > 0)위와 같이 괄호가 여러개 조건절이 있을 때, 성능저하가 일어날 수도 있다.
연능괄호,단능괄호 매칭이 잘 되었는지 확인해야한다.
5. 조인조건 vs. 검색조건, 임의 쿼리 식별자 달기
SELECT
o.OrderID, o.CustomerID, *
FROM
dbo.Customers AS c
LEFT JOIN
dbo.Orders AS o ON c.CustomerID = o.CustomerID
WHERE
c.CustomerID IN ('FISSA', 'PARIS', 'ANTON')
AND o.CustomerID IS NULL
SELECT
o.OrderID, o.CustomerID, *
FROM
dbo.Customers AS c
LEFT JOIN
dbo.Orders AS o ON c.CustomerID = o.CustomerID
AND o.CustomerID IS NULL --customer id가 null이면 left join
WHERE
c.CustomerID IN ('FISSA', 'PARIS', 'ANTON')위의 쿼리에서 and o.CustomerID is NULL 위치가 다른 것을 알 수 있다.
첫번째 쿼리는 where 절, 두번째 쿼리는 조인절에 위치한다.

결과도 다르게 나오는데, 첫번 째 쿼리는 검색 결과에 대한 집합 값을 가져오게 하고, 두번째 쿼리는 customer id 끼리 조인하면서 null 값인 결과를 출력한다. 두번째 쿼리 where 절 전까지 출력했을 때, 모든 고객의 주문 order 컬럼값이 모두 null로 나온다.

- 호출 식별자 관련
-- 애플리케이션 코드
string sql = @"
SELECT OrderID, CustomerID, OrderDate
FROM dbo.Orders
WHERE OrderDate >= @startDate
AND OrderDate < @endDate
--OrderHistory.GetMonthlyOrders"; // 어떤 기능에서 호출된 건지 표시이렇게 하면 나중에 성능 문제나 버그가 발생했을 때 주석을 보고 "OrderHistory 클래스의 GetMonthlyOrders 메서드"를 바로 확인할 수 있다.
6. Semenatic Error
의미오류는 식별하기가 어려운데, 쿼리 자체 문제는 없으나 결과가 작성자의 의도와 다르게 만들어지는 것을 의미한다.
1) not in 과 null
SELECT
e.EmployeeID
FROM
dbo.Employees AS e
WHERE
e.EmployeeID NOT IN (SELECT m.ReportsTo FROM dbo.Employees AS m);not in 안의 select문을 실행했을 때 아래처럼 결과가 나온다.
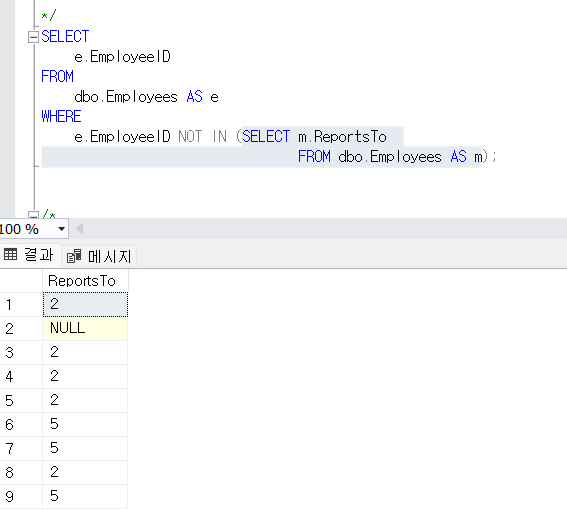
그리고 밖의 select문을 실행하면 다음과 같은 결과가 나온다

전체를 실행하면, 결과는 unknown으로 나온다.

이렇게 나오는 이유는, not in 사용시 null이 있기 때문이다. null을 not으로 비교하는 작업이 일어나기 때문에, null 처리를 is null 조건을 별도로 처리하거나 not exists를 사용하는것이 좋다.
2) 서브쿼리 내 잘못된 외부 열 참조
서브쿼리 안에서 참조하는 컬럼이 테이블에 있는 컬럼이 아니라 외부 쿼리에 있는 테이블 컬럼을 참조하는 경우이다.
in 안의 서브쿼리를 실행했을 때는 문법 에러가 나오지만, 전체를 실행했을때 서브 쿼리 안에서 외부 테이블의 컬럼을 참조할 수 있다. orderdate의 모든 결과값이 출력된다. 결국은 SELECT OrderDate FROM dbo.Orders 와 같은값이 나온다.
SELECT
OrderDate
FROM
dbo.Orders
WHERE
OrderID IN (SELECT OrderID FROM dbo.Customers);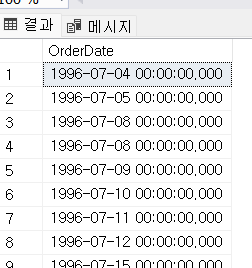
3) INNER 조인에 해당하는 OUTER 조인
조인절까지 실행했을 때 다음과 같은 결과가 나온다
SELECT
m.EmployeeID AS RptsTo, m.LastName, e.EmployeeID, e.Title
FROM
dbo.Employees As m
LEFT JOIN
dbo.Employees AS e ON m.EmployeeID = e.ReportsTo
WHERE
e.Title = 'Sales Manager';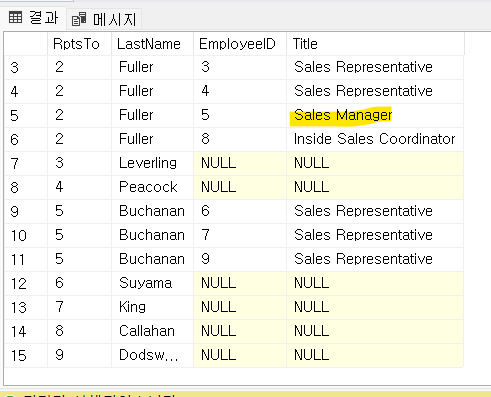
where 절 까지 실행하면 sales manager에 해당하는 5행만 가져오게 되는데, 다른 행들은 의미가 없게 된다.
실행계획을 살펴보면 inner join이 된 것을 알 수 있다. 불필요한 outer join을 사용한 것이다.
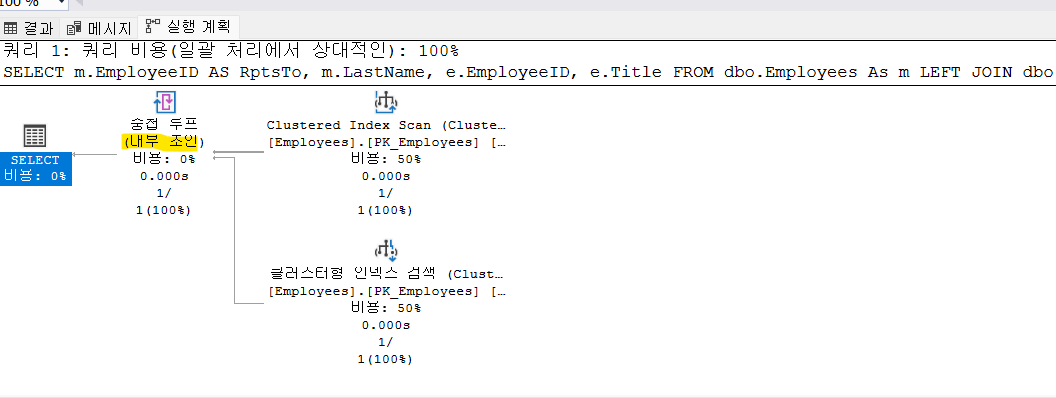
3) 동의 반복
사실상 이 쿼리는 실행하지 않아도 where 절 둘다 2 초과를 나타내고 있다는 것을 알 수 있다.
불필요하기 때문에 하나만 나타내는 것이 좋다.
SELECT
OrderDate
FROM
dbo.Orders
WHERE
ShipVia > 4 OR ShipVia > 2;
4) 불필요한 문장 사용
customer id는 pk 이기 때문에 distinct를 사용할 필요가 없다
SELECT DISTINCT
CustomerID, CompanyName, ContactName
FROM
dbo.Customers;
QUICK을 = equal로 쓸수 있는데 불필요하게 like 패턴식으로 쓴 케이스다
최대한 딱 필요한 조건만 넣어서 부하가 걸리지 않게 하는 것이 좋다
SELECT
OrderID, OrderDate, CustomerID
FROM
dbo.Orders
WHERE
CustomerID LIKE N'QUICK';
OrderID,ProductID 모두 PK 이기 때문에 UnitPrice 까지 order by 절에 넣을 필요가 없다.
SELECT
OrderID, ProductID, UnitPrice
FROM
dbo.[Order Details]
ORDER BY
OrderID,ProductID, UnitPrice
5) 불필요한 UNION
where절을 보면 겹치는 데이터가 없다.
union의 역할은 중복 원소를 제거하는 집합연산에 해당이 되는데 중복할 데이터가 없다.
이 경우에는 UNION ALL을 쓰는 것이 좋다.
SELECT
OrderID, OrderDate
FROM
dbo.Orders
WHERE
OrderID <= 10250
UNION
SELECT
OrderID, OrderDate
FROM
dbo.Orders
WHERE
OrderID >= 11070;
출처: 인프런 SW 개발자를 위한 성능 좋은 SQL 쿼리 작성
'SQL' 카테고리의 다른 글
| II. 쿼리 금기사항 (0) | 2025.01.06 |
|---|