A Lightweight CNN Model for Detecting Respiratory Diseases from Lung Auscultation Sounds using EMD-CWT-based Hybrid Scalogram [IEEE JOURNAL OF BIOMEDICAL AND HEALTH INFORMATICS,2020]
티스토리 두 달만에 쓰다니 진짜 반성할게요
최근에 다른 인공지능 동아리를 시작해서 medical AI 팀에 들어갔다. sound signal 분야는 처음인데, 이번 계기로 새로 알게되는 점이 많을 것 같다.
논문 출처 : https://arxiv.org/pdf/2009.04402
Abstract
이 논문에서는 경량화된 컨볼루션 신경망(CNN) 아키텍처를 제안하여 폐 호흡의 hybrid scalogram features 기반 특징을 사용해 호흡기 질환을 분류한다. hybrid scalogram features 이란 , empirical mode decomposition (EMD) 와 continuous wavelet transform (CWT)를 사용한다.
모르는 용어 탐색:
Empirical Mode Decomposition (EMD) 는 비선형 비정상 신호를 분석하기 위한 방법으로, 원시 신호를 여러 개의 내재 모드 함수(Intrinsic Mode Functions, IMFs)로 분해한다. EMD는 데이터 기반의 접근법으로, 신호의 특성을 고려하여 자동적으로 분해를 수행한다.
Continuous Wavelet Transform (CWT)는 신호의 시간-주파수 분석을 수행하는 방법으로, 신호를 다양한 주파수 대역에서 분석할 수 있게 해준다. 웨이블릿 함수(모양이 다양하고 국소적인 특성을 가진 함수)를 사용하여 신호를 변환한다.
오픈된 ICBHI 2017 lung sound dataset을 이용하여 연구를 수행했다. scoring은 삼원 만성 분류(건강, 만성, 비(non) 만성)에서 가중치를 적용한 acc score가 99.20%, 6개로 나눈 병리 분류 점수는 99.05% 의 정확도를 달성했다. VGG16을 쓴 것 보다 각각 0.52, 1.77%가 더 높은 정확도를 보여주었다.
Introduction
폐음의 쌕쌕거리는 소리로 비정상적인 폐음인 것을 알 수 있다. 주파수, 음정, 에너지, 강도, 음색 및 음악성을 기준으로 구분할 수 있다. 폐음은 특정 호흡기 질환을 인식하는 데 중요하다. 하지만 미묘한 차이는 전문가에게도 어려울 수 있어, 인공지능으로 이 미묘한 차이를 탐색하는데 도움이 된다. 하지만 인공지능을 학습할 때, 적절한 기능성을 얻기 위해서는 많은 시간과 강력한 컴퓨팅 자원이 필요하다. 양자화, 경량화, 낮은 정밀도 등의 방법을 사용해 파라미터를 줄여 학습의 무게를 줄인다. 이 연구에서는 경량화된 CNN 아키텍처를 사용한다. 호흡기 질환 분류 시 삼원 분류와 6개의 병리 classification을 진행한다. 호흡 소리 신호에서 scalogram을 얻기 위한 하이브리드 접근 방식을 사용했는데, 여기서 cwt는 EMD 호흡음 신호의 최대 상관관계 내재 모드 함수(IMF)에 대해서만 수행된다. 그 후 CNN 모델과 함께 VGG16과 같은 복잡한 CNN 모델이 사용된다. AlexNet 및 MobileNet V2 , NASNet , ShuffleNet V2 등 여러 최신 경량 아키텍처를 사용한다. 다양한 범주의 호흡기 질환을 감지하기 위해 스칼로그램 이미지를 분류한다.

MATERIALS AND METHODS
ICBHI 2017 Dataset
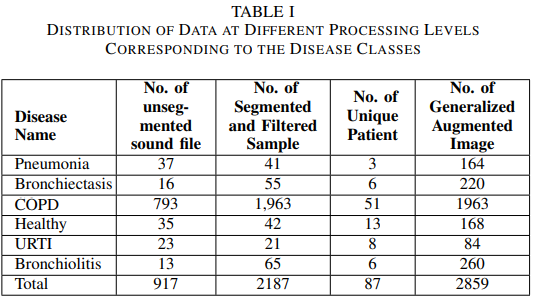
ICHBHI(International Conference on Biomedical Health Informatics) 2017 데이터베이스는 오픈 데이터로 폐 청진음 데이터 이다. 이 데이터셋은 5.5시간의 오디오 기록이 있는데, 각각 다른 주파수(4kHzm 10kHz, 44.1kHz)를 가지고 있고, 다른 장비로 다른 해부학적 위치의 오디오 샘플이 126개 주제, 920개 있다.
이 샘플들은 두 가지 주제로 나눴는데, 첫번째는 환자의 병리학적 상태(7개의 병 분류: 폐렴, 기관지확장증, COPD, 요로감염, 세기관지염, 천식 등) / 두번째는 각 호흡 주기에서 딱딱거림과 쌕쌕거림에 따라 호흡기 이상 유무로 나누었다.
Data Prepossessing
1) Noise filtering: 폐 청진 신호의 주파수 범위는 50 Hz에서 2500 Hz로 알려져 있으므로, 녹음된 오디오 신호는 6차 Butterworth bandpass filter를 사용하여 필터링된다. 이를 통해 50 Hz에서 2500 Hz 주파수 성분만을 유지한다. 이후 모든 샘플 신호는 일관성을 확보하기 위해 22050 Hz로 재샘플링되며, 장치의 동질성을 위해 [-1, 1] 범위로 정규화한다.
- Butterworth bandpass filter: 신호 처리에서 널리 사용되는 필터의 한 종류로, 특정 주파수 범위만을 통과시키고 나머지 주파수는 차단하는 역할을함
2) Segmentation of the sound data: 각 오디오 녹음은 호흡 주기에 따라 6초 단위로 분할된다. 유용한 호흡음 정보를 얻기 위해 최소 호흡 주기 길이가 3초인 샘플만 고려된다. 이후 두가지 질병 분류인 천식과 하기도 감염은 샘플이 부족하여 제외했다. 120명의 독립 환자 중 87명의 폐 청진음을 활용하였다.
Feature extraction
1) Empirical Mode Decomposition (EMD): EMD는 시간 척도와 에너지 분포 측면에서 특히 강력한 자기 적응 신호 분해 방법으로 폐음과 심장음과 같은 비선형 및 비정상 신호의 분석 및 처리에 매우 적합하다. EMD는 주어진 신호 x(t) 를 신호의 지역적 특성 시간 척도에 따라 내재 모드 함수(Intrinsic Mode Functions, IMF)인 ( IMF1(t), IMF2(t), ..IMFN(t) )로 분해한다. 원래 신호를 모든 IMF의 합과 최종 트렌드(단조적이거나 상수인 잔여값 ( r(t) ))로 표현한다.

IMF는0에 대해 대칭적이어야 한다.
2) Continuous Wavelet Transform (CWT): 웨이블릿 변환은 신호를 직교 정규 웨이블릿 기저나 독립된 주파수 채널 집합으로 분해할 수 있다. 기본 기능인 mother wavelet과 그것의 scaled되고 확장된 버전을 사용하여 cwt는 유한한 에너지 신호(x(t))를 다음과 같이 분해한다.
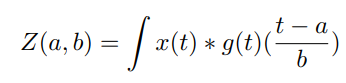
여기서 b는 시간, a는 스케일 factor 이다. 스케일값이 클수록 저주파가 작다. CWT 계수 Z의 제곱 계수를 scalogram이라고 한다.
Scalogram Representations
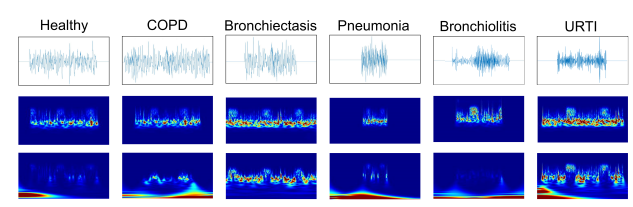
1) Conventional Scalogram: Scalogram은 CWT를 사용하여 얻은 에너지 밀도를 나타내는 신호의 시간-주파수 표현으로 정의된. 분할되고 필터링된 폐 소리 샘플은 MATLAB 에서 Morse analytic wavelet을 사용하여 해당 웨이블릿 계수로 분해다. 이러한 계수를 이용하여 해상도 224x224의 스칼로그램 플롯이 생성된다. 아래 그림은 다양한 질병 범주에서의 폐 소리의 스칼로그램이다.
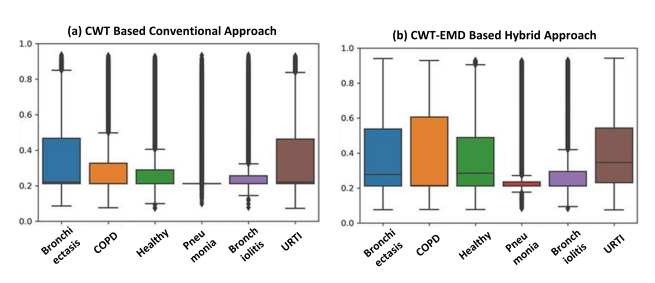
2) Hybrid Approach for Scalogram: 각 병리 class에서 분리되고 필터링 샘플은, MATLAB의 EMD 함수를 사용하여 9개의 IMF를 생성한다. 소스 신호와 IMF 간의 교차 상관관계에 따라 상관계수가 가장 높은 IMF 출력이 결정된다. 그 후, 해당 IMF의 CWT의 제곱 계수를 계산하여 스칼로그램을 계산한다. 각기 다른 주파수 대역이 최대 범위에서 최소 범위까지 다양하게 변함에 따라, 내재 모드 함수(IMFs)는 시간 및 주파수 정보를 효과적으로 추출할 수 있는 능력을 갖추게 된다. 따라서 IMF 기반 방식과 CWT 중심의 스칼로그램 표현이 결합되면, 새롭게 형성된 하이브리드 스칼로그램은 더 차별적이고 중요한 특징을 보여줄 수 있다. 이는 CNN 모델을 통한 더 나은 분류 성능을 제공할 잠재력이 있다. 아래 사진에서 하이브리드 접근 방식을 사용할 때 전통적인 CWT만을 사용한 스칼로그램보다 플롯 간의 구분이 더 뚜렷하게 나타난다.
Augmentation
ICBHI 2017 dataset은 매우 불균형하며, 약 86%의 데이터가 COPD에 속한다. 대표성이 낮은 클래스를 오버샘플링하고 ,데이터 불균형 문제를 해결하기 위해 이미지 증강이 사용된다. 데이터 갯수가 낮은 범주의 오디오 샘플에서, 각 분할 샘플에 대해 네 가지 색상 매핑 방식(Parula, HSV, Jet, Hot)을 사용하여 네 개의 스칼로그램이 생성된다. 반면, 가장 많은 양을 차지하는 범주인 COPD는 각 오디오 샘플에서 하나의 이미지만 생성된다. 그러나 데이터의 일반화와 동질성을 보장하기 위해 COPD에 대해서도 네 가지 색상 매핑 방식이 무작위로 사용된다.
PROPOSED LIGHTWEIGHT CNN ARCHITECTURE
224* 224개의 이미지의 3채널 입력에 해당하는 입력 레이어로 이루어진 제안된 cnn 모델은 아래와 같다.

1차 합성곱(convolutional) 층은 55픽셀 크기의 커널을 가진 64개의 출력 필터를 사용하며, 그 뒤에 22픽셀 크기의 맥스 풀링(max-pooling) 층이 이어진다. 첫 번째 층 위에 3개의 추가 합성곱 층이 쌓이며, 각각 33픽셀 크기의 커널을 사용하고 필터 수는 64, 96, 96개로 순차적으로 설정된다. 각 층에는 배치 정규화(batch-normalization)와 22픽셀 풀링 윈도우를 가진 맥스 풀링 층이 포함된다. 이 모든 층의 출력은 평탄화(flattening)되어 다섯 쌍의 완전 연결층(Fully-connected layer)과 드롭아웃(dropout) 층과 연결되며, 마지막으로 각 클래스에 대한 확률 노드를 가진 소프트맥스(SoftMax) 출력 층이 있다. 맥스 풀링은 ReLU 활성화 이후에 사용되어, 추출된 특성 맵의 공간 차원을 줄이고 가장 중요한 특성을 추출하며 위치적 편향에 영향을 받지 않는다. 데이터의 다양성 문제를 극복하기 위해, 각 합성곱 층과 함께 배치 정규화 층이 추출된 특성을 정규화한다. 이는 적은 수의 매개변수로도 네트워크의 표현력을 높이고 훈련 속도를 빠르게 한다.
EXPERIMENTAL RESULTS
Evaluation Criteria
증강된 이미지 세트는 모델 하이퍼파라미터의 훈련 및 미세 조정을 위해 80%는 훈련용, 20%는 검증용으로 나누어진다. 환자의 고유성은 실제 응용에서 중요한 요소로, 훈련 및 검증 부분을 나눌 때 유지되어야 한다.
분류기 모델의 성능은 정확도, 재현율(민감도), 정밀도, F1 점수와 같은 잘 알려진 평가 지표를 기반으로 평가한다. 추가로, 민감도와 특이성을 모두 고려하여 ICBHI 데이터 세트를 사용한 성능 평가를 위한 전용 지표인 ICBHI 점수도 사용된다.
Experimental Setup
미니배치 훈련 방식을 적용하여 이미지 데이터를 모델에 공급하며, 클래스 불균형 문제를 해결한다. 이 기법은 데이터가 적은 클래스는 오버샘플링하고 데이터가 많은 클래스를 무작위로 언더샘플링한다. 이를 통해 CNN 모델은 각 훈련 에폭마다 각 클래스에서 동일한 수의 샘플을 취하여 균형 잡힌 훈련 세트를 형성한다. 학습률 0.00001의 옵티마이저(Adam)가 사용된다. 배치 크기는 각 훈련 및 검증 배치에서 3개와 6개의 데이터 클래스에서 동일한 수의 샘플을 취하기 위해 6의 배수여야 한다. 본 연구에서는 분류 방식의 훈련 및 검증을 위해 배치 크기로 6이 사용되었다.
이전에 언급한 것 처럼 본 연구에서는 삼원 만성 분류(만성, 비만성, 건강)와 여섯 가지 병리학적 분류(기관지 확장증, 세기관지염, COPD, 건강, 폐렴, 상기도 감염)를 수행한다. 제안된 CNN 모델의 분류 성능은 이미지 분류에 잘 알려진 CNN 아키텍처인 VGG16과 비교된다. 실험은 전통적인 CWT 기반 스칼로그램 이미지와 하이브리드 스칼로그램 이미지를 모두 사용하여 수행됩니다. 또한, 제안된 CNN 모델의 성능은 VGG16, AlexNet 및 여러 경량 네트워크와 함께 계산 복잡성과 정확도 측면에서 비교된다.
Classification Performance of the Proposed Framework
1) Chronic Classification: 아래표(table 2)에서 하이브리드 스칼로그램 방법과 제안된 CNN 모델 분류기를 결합했을 때 가장 높은 정확도인 99.21%를 나타낸다. VGG16을 사용한 경우의 정확도는 98.89%로 거의 비슷하다. 하지만 VGG16의 비교적 낮은 정확도는 다양한 클래스의 이미지 수가 제한되어 있어 과적합 문제 때문으로 보인다. 전통적인 CWT 스칼로그램과 제안된 하이브리드 스칼로그램을 비교할 때, 후자가 VGG16과 제안된 CNN 모델 모두에서 9.5%-11.4%의 정확도 향상이 뚜렷하게 나타다. 두 모델의 최상의 결과에 대한 혼동 행렬은 그림 5에 나타나 있으며, 제안된 방법이 VGG16보다 세 가지 만성 분류에서 더 우수함을 보여준다.
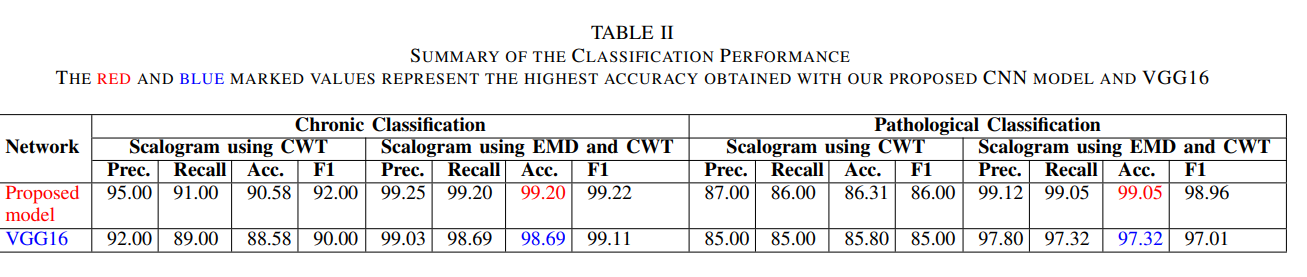

2) Pathological Classification: 여섯 가지 병리학적 분류에서 하이브리드 스칼로그램과 제안된 CNN 모델 분류기를 사용하는 방법은 99.05%의 최고의 정확도를 달성한다(table 2 참조). 세 가지 만성 분류와 유사하게 VGG16의 정확도는 약간 낮다. 그러나 데이터셋이 여섯 가지 질병 클래스로 나뉘면서 분리되기 때문에 정확도 감소가 더 눈에띈다. 제안된 하이브리드 스칼로그램은 VGG16과 제안된 모델 모두에서 전통적인 CWT 스칼로그램보다 13.4%-14.7% 더 높은 성능을 보인다. 전반적으로 제안된 방법이 더 나은 성능을 제공한다.
CONCLUSION
연구에서는 폐음의 스칼로그램 이미지를 사용하여 호흡기 질환을 분류하는 경량 CNN 모델을 제안했다. EMD와 CWT를 결합한 하이브리드 접근 방식이 스칼로그램 이미지를 생성하는 데 사용되다. 공개된 ICBHI 2017 챌린지 데이터셋을 활용하여 만성 및 병리학적 분류를 수행하였으며, 만성 분류에서 99.21%의 높은 정확도를, 여섯 가지 질병 클래스의 병리학적 분류에서 99.05%의 정확도를 달성했다. 이 정확도는 훨씬 더 큰 네트워크인 VGG16보다 높다. 또한, Precision, Recall, F1-score, 민감도, 특이성 및 ICBHI 점수 측면에서 기존의 최첨단 방법들과 비교하여 더 나은 또는 동등한 성능을 제공한다. 특히, 제안된 기술의 분류 성능은 환자 측면에서 훈련 및 테스트 데이터가 독립적으로 평가되었다는 점이 주목할 점이다. 제안된 분류기의 계산 복잡성은 여러 잘 알려진 CNN 모델 및 경량 네트워크와 비교되었으며, 경량 깊이 구조임에도 불구하고 높은 분류 정확도를 달성하는 것으로 나타났다. 이러한 특성은 실제 임상 응용에서 폐 청진을 통한 호흡기 질환의 자동 분류 개발에 기여할 것으로 기대된다.