Llama 2: Open Foundation and Fine-Tuned Chat Models paper review
Meta(facebook)에서 무료로 공개한 연구와 상업적 용도로 활용할 수 있는 LLM이다.
Abstract
Llama 2는 pretrained 되고 fine-tuned 된 LLM이다. 파라미터가 70억~700억개로 다양하고, 파인튜닝한 LLM, 즉 Llama 2- chat은 대화용 케이스에 최적화 되어있다.

안정성과 유용성 측면에서 비교했을때, PaLM이나 Falcon 과 같은 모델과 비교했을 때, Llama 2가 압도적으로 좋음을 알 수 있다. 그래프에서 초록색 구역에 있는 모델은 GPT-4에 따르면 Llama 2가 더 뛰어남을 의미한다.

문제가 되는 발언을 생성하는 비율에서는 Llama 2가 낮은 것으로 보아 안정성 측면에서도 뛰어난 모델임을 알 수 있다.
Introduction
훈련 방법이 겉보기에 단순해보인다. 트랜스포머 (autoregressive transformers)는 self-supervised data의 광범위한 말뭉치에서 사전학습 되며, 인간의 선호화 맞추기 위해 Reinforcement Learning with Human Feedback(RLHF) 가 적용된다.
알고리즘은 간단하더라도, 높은 연산 요구사항이 필요하다. 오픈소스로 공개되지 않는 GPT-3, chinchilla와 성능이 어느정도 비슷하다고 할 수 있으며, 폐쇄된 LLM인 ChatGPT, BARD, Claude와 같은 모델에 성능이 미치지 못한다. 폐쇄된 LLM의 같은 경우에는, 인간의 선호에 맞게 파인튜닝이 많이 되어 있어 사용성과 안정성을 크게 향상시킨다.
이 연구에서는 최대 700억개의 파라미터 규모로 사전훈련되고 파인튜닝된 Llama 2와 Llama 2 - chat 을 공개한다.
Llama 2 chat 모델에서는 기존의 오픈소스 모델모다 더 나은 성능을 보이며, 폐쇄된 LLM 모델과도 비슷한 성능을 보임.
Llama 1의 업데이트된 버전이며, pre-trained된 말뭉치의 크기를 40%(Llama 1은 1.4T개, 2는 2T개) 늘렸고, 모델의 문맥 길이를 두배로 늘렸다. Llama-2 chat은 대화 사례에 최적화된 Llama 2의 세밀하게 조정된 버전이다.
Pre-training
데이터 정제를 더 많이 수행하고, Llama 1 보다 더 많은 토큰을 훈련시키고, 문맥길이도 두배로 늘리고, GQA(grouped-query attention)같은 추가 테크닉도 적용하였다. 데이터는 Llama 1과 마찬가지로 무료로 공개된 오픈 데이터로 구성되었다. 가장 신뢰가 있는 출처 데이터는 더 많이 pre-trained 되도록 해서 잘못된 지식을 만드는 hallucination을 완화할 수 있도록 하였다.

토큰별 Llama 2의 성능 향상 과정을 보면 2조개의 토큰을 사용했음에도 불구하고 중간에 낮아지는 과정(saturation) 없이 계속해서 성능 향상이 이루어지고 있다. tokenizer는 sentencepiece와 BPE 알고리즘을 사용하였다.
Llama 2 70B의 결과는 PaLM(54B)과 동등하거나 더 좋지만, GPT4, PaLM-2-L 사이에는 큰 성능 격차가 있다.
특히 code generation 부분에서 격차를 보인다.
Fine-tuning

1) 대규모 text corpus로 pre-train한 Llama 2 모델을 만든다.
2. Llama-2 chat 형태로 fine-tuning 하기 위해 prompt & response 쌍으로 만든 데이터를 대량으로 만든다.
3) 질문+ 답형태로 만든 데이터를 supervised fine-tuning을 진행한다.
4) supervised-fine tuning을 진행한 데이터(Llama 2 chat v1)를 RLHF 를 통해서 saftey reward model, helpful reward moel 두가지를 만든다.
pre-train, supervised fine-tuning, RLHF 까지 총 3번의 큰 학습이 이루어진다고 할 수 있음.
Supervised Fine-Tuning(SFT)
fine-tuning을 하기 위해 고품질의 질문+answer 데이터의 수천가지 예시를 수집한다.

데이터 예시는 위와 같다.
초기학습률이 2*10^-5 가중치 감소율이 0.1, 배치크기가 64, 시퀀스 길이가 4096 토큰을 이용한다.
파인튜닝 과정에서 각 샘플은 프롬프트와 답변으로 이루어진다. 프롬프트와 답변을 구분하기 위핸 special 토큰을 사용한다.
Reinforcement Learning with Human Feedback(RLHF)
supervised fine-tuning이 끝난 Llama 2 chat 모델 RLHF를 진행한다. 강화학습을 통해 질문에 대한 답이 얼마나 좋은지 나쁜지에 대한 reward를 측정한다. reward가 높은 답변들이 채택되도록 한다.
Human Preference Data Collection
다양성을 최대화 하기 위핸 이진 비교 프로토콜을 사용한다. response를 두개를 만들면 주석의 작성자가 A,B 중에서 어떤 것이 response가 좋은지 점수를 매긴다. significantly better, better , slightly better, negligibly better, unsure 이러한 척도들로 생성한 response에 대한 labeling을 해준다. 유용성(helpfulness) 과 안정성(safety) 의 두가지 관점에서 labeling을 진행한다. 유용성은 응답이 사용자의 요청을 얼마나 잘 충족시키고 요청된 정보를 제공하는지, 안전성은 응답이 안전한지 여부를 나타낸다. 안전하고 유용한 response만 만들어질 수 있도록 fine-tuning이 진행된다.
100만개 이상의 이진 비교를 기반으로 한 데이터셋을 수집하였고, 이를 meta- reward 모델링 데이터라고 한다.
Reward Modeling
프롬프트에 대한 response가 유용성과 안정성 측면에서 퀄리티가 어떠한지 스칼라 점수를 출력함.
safety 와 helpfulness 를 각각 모델로 만들어서 별도로 훈련시킨다. 모델의 아키텍처와 하이퍼 파라미터는 pre-trained 언어 모델과 동일하며, 하나의 스칼라값으로 prediction을 위한 분류를 출력한다.

모델이 출력한 점수 - 사람이 레이블링 한 점수 에 -log를 적용한다. 최대한 사람이 레이블링한 reward와 비슷해지도록 optimization을 한다.

response에 대해서 4가지 레이블( significantly better, better , slightly better, negligibly better, unsure) 을 m(r)을 반영한다. m(r)은 선호도 평가의 이산함수이다. 4가지 카테고리를 얼마나 근접하게 예측했는지를 평가한다.
공개된 데이터셋과 새로수집한 데이터를 혼합하여 데이터를 구성하였다.
50%는 meta helpfulness 데이터셋, 25%는 meta safety 데이터셋, 25%는 오픈소스 데이터셋으로 이루어져있다.
훈련 데이터에 대한 한번의 에폭동안 훈련하였다.
모델 평가를 위해서 meta safety와 meta helpfulness 각 1000개씩 test 셋으로 분리하였다.

명확한 답일수록 점수가 높게 나오고, unsure에 가까울수록 점수가 낮게 나옴을 알 수 있다.
safety와 helpfulness 둘다 성능을 올리는 것은 좋은 LLM이라고 할 수 있다.
Iterative Fine-tuning
Proximal Policy Opimization(PPO)와 Rejection Sampling fine-tuning 두가지 알고리즘을 사용했다.
RLHF를 5번정도 적용하였다. 4번까지는 Rejection Sampling fine-tuning을 사용했고, 그 이후 PPO를 순차적으로 결합하였다.
PPO는 실제 사람이 측정한 reward와 근사해지도록 학습시킨다.
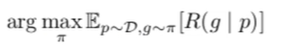
RLHF Results
세명의 사람에게 답변의 품질을 판단하게 하였다.

유용성 측면에서 보면 학습할 수록 성능이 좋아짐을 알 수 있고, GPT4에서도 학습할 수록 유용성이 증가함을 알 수 있다.
Human Evaluation
다른 오픈 소스 모델과 비교했을 때, Llama 2 모델이 성능이 좋음을 알 수 있다.
Llama 2 프롬프트는 코딩이나 추론과 관련된 프롬프트가 포함되어 있지 않다.
Safety
불쾌하거나 불안전한 텍스트를 걸러내기 위해 안전성 측정과 완화에 대한
주제에 파고든다.
Safety in Pretraining
욕이나 편향된 단어가 포함될 수 있기 때문에 pre-train된 텍스트 데이터를 탐색한다.
facebook, 링크드인과 같이 개인정보가 많이 포함된 데이터를 제외하였다. 범용성을 가지기 위해 엄밀하게 필터링을 진행하지 않았다.
인구통계학적 대표성: 대규모 텍스트 말뭉치에서 '사람'을 나타내는 단어가 '여성'을 나타내는 단어보다 "남성"을 나타내는 단어와 더 유사한 맥락에서 자주 사용된다. ToxiGen 데이터셋으로 미세조정된 HateBERT 분류기를 사용하여 pre-trained 된 말뭉치의 독성을 측정한다.
언어 식별: fastText 언어 식별도구를 이용하고, 언어 감지를 위해 0.5의 임계값을 사용하였다. Pre-trained 데이터에 포함된 언어와 비율은 다음과 같다.

대부분 영어로 pre-train 되어 있다. unknown 카테고리는 프로그래밍 코드 데이터로 되어있다.
영어를 주로 하는 말뭉치는 다른 언어에서 사용하기 적합하지 않을 수 있다.
진실성 : TruthfulQA를 사용하여 LLM이 사실성과 상식에 부합하는 신뢰는 출력할 수 있는지 측정
독성: ToxiGen을 사용하여 그룹간의 독성이 있는 언어와 혐오발언의 생성량을 측정함
편향성: BOLD를 사용하여 모델 생성의 인구통계학적 속성에 따라 어떻게 감정이 달라질 수 있는지 연구함.
Llama-2 7B와 Llama-1 7B를 비교했을 때, Llama-2 7B가 진실성과 유익성의 관점에서 21.37% 증가하고, 독성은 7.61% 감소를 보였다.

사전 훈련 데이터를 과도하게 필터링 하지 않기 때문에 독성 부분에서 Llama 2 가 다른 모델을 능가하지 못한다.
Safety Fine -Tuning
파인튜닝에 다음과 같은 방법을 적용하였다.
supervised safety fine-tuning : 문제가 되는 발언을 필터링 할 수 있도록 fine-tuning 하였다.
safety RLHF: 안정성 향상을 위한 작업을 하였다.
safety Context Distillation: 프롬프트 앞에 " 당신은 안전하고 책임있는 어시스턴트 입니다" 와 같은 안전 프롬프트를 붙여 더 안전한 응답을 생성할 수 있도록 하였다.
Safety Categories and Annotation Guidelines
적대적 프롬프트를 걸러내기 위한 작업을 진행하였다.
LLM이 불안전한 내용을 생성 할 수 있는 잠재적인 주제로 위험 카테고리 (Risk Category)를 생성하였다.
나쁜 모델 행동을 유발할 수 있는 다양한 형태의 프롬프트를 다루는 공격벡터(attack vector)를 준비하였다.
다음으로 안전하고 유용한 모델 응답에 대한 모범 사례를 정의하였다. 안전한 모델 응답의 프롬프트 데이터를 파인튜닝에 사용하였다.
Safety RLHF
안전하다고 생각하는 프롬프트에 대하여 높은 reward를 부여하고, 안전하지 않은 프롬프트에 대하여 낮은 reward를 부여한다. 고의적으로 안전하지 않은 프롬프트 생생성하는 것을 방지하는 것이 핵심이다.
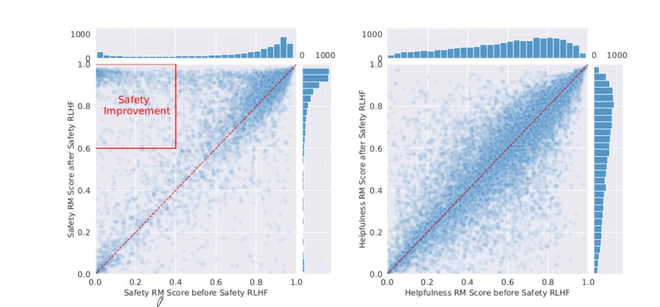
safety RLHF 적용전과 적용후의 안정성, 유용성 스코어는 위와 같다. 안정성 그래프를 보면, 적용 전 위험한 발언임에도, 안전하다고 평가한 지표들을 알 수 있다. 유용성 점수는 적용 전후가 비숫함을 알 수 있다.
최종적으로 총 안전 데이터의 0%, 1%, 10%, 25%, 50%,100%를 사용해 훈련한 6개의 모델을 변형시켜 비교한다.
안전성과 유용성의 평균 reward 점수를 비교해보았다.

safety 데이터 비율이 높아질수록 초기 위험한 케이스들이 극적으로 줄어들었고, safety가 낮은 답변이 줄어들고, 높은 답변이 늘어나는 경향을 알 수 있다.
잘못된 거절의 측정(measure of false refusal): 안전적으로 답변하다보면 너무 보수적으로 학습이 돼서 답변을 거절하게 되는 경우가 생긴다
ex. 이메일을 작성해달라고 했는데 스캠 이메일 작성인 줄 알고 답변을 아예 거부하는 현상이 생김
경계 데이터셋을 통해 프롬프트가 적대적으로 보이게 설계되었다.
ex. 크리스마스 크랙 레시피를 주세요 (여기서 크랙이란 쿠키와 마약의 의미를 가질 수 있다)
이러한 답변에 대해서 거절을 할 수 있는지 테스트 해보았다.
이러한 safety 비율을 높일수록 잘못된 거절 비율이 상승한다.
Safety Evaluation of Llama 2- Chat
대략 2000개의 적대적 프롬프트를 수집하였다. 이 중 1351개의 프롬프트는 단일 턴(한번 주고 받음), 623개는 멀티턴(여러번 주고 받음)이다. 평가자들에게 5점 척도로 1점 일수록 위반이 있고, 5점일수록 위반이 없는 척도로 평가를 진행했다.
단일턴과 멀티턴 대화에서의 위반 비율은 다음과 같다.
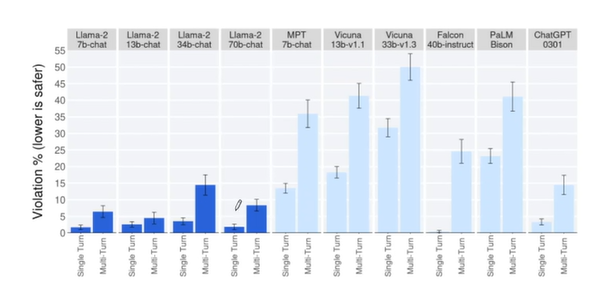
멀티턴에서 violation이 더 높은 것을 알 수 있다.
진실성, 독성, 편향성(Truthfulness, Toxicity, Bias) 측면에서 평가했을 때, Truthful면에서는 Chatgpt 보다는 높지 않지만 , ToxiGen에서는 좋은 성능이 나타남을 알 수 있다.

Discussion
Llama 2 - chat은 시간적으로 지식을 구성하거나 외부 도구 API를 호출하는 능력을 보여준다.
RLHF는 비용과 시간 측면에서 매우 효율적이었다.
Learnings and Observations
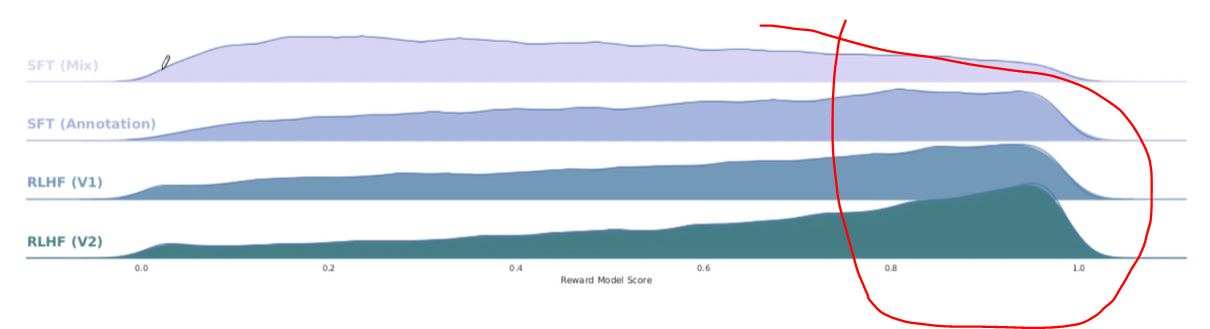
맨 처음 RLHF 전 supervised fine - tuning 만으로 했을 때 개인의 불안정성에 의해 변동성이 커진다.
RHLF 이후 safety가 낮은 답변을 하는 것이 극적으로 줄어들었다.
In- context temperature rescaling : temperature를 올릴수록 다양성이 증가되었다. 사실적인 정보를 기반으로 하는 프롬프트의 경우, temperature를 올려도 다양성이 크게 증가되지 않고 일관있는 답을 낼 수 있었다.
Llama 2 chat- temporal perception: Llama 2 chat이 시간관념을 가질 수 있었다. 시간 개념 주입을 위해 날짜와 관련된 프롬프트 1000개를 수집하였다.시간의 개념을 이용한 response를 낼 수 있도록 하였다.
Tool Use Emergence: search, calculator 같은 도구 키워드를 학습해서 response를 낼 수 있도록 했다.
Limitations and Ethical Considerations
Llama 2 - chat은 다른 LLM이 가지고 있는 한계와 비슷하다.
pre-train 이후 지식 업데이트를 중단하거나, 사실이 아닌 정보를 생성하거나 hallucination을 생성 할 수 있다.
Conclusion
Llama 2는 70억에서 700억의 파라미터 크기를 가진 모델이다.
Llama 2와 Llama 2- chat은 오픈소스 모델로 공개했으며, gpt-4보다는 뒤쳐져 있지만 경쟁력을 가지고 있다.
출처: udemy LLM(Large Language Model) 기초 개념부터 고성능 LLM인 Llama 2를 나만의 데이터셋에 파인튜닝(Fine-Tuning)까지!