MNIST 활용한 숫자 인식
출처: 차근차근 실습하며 배우는 파이토치 딥러닝 프로그래밍
여기서 transforms를 이용하여 진행할 데이터 전처리는 다음과 같다.
- 값의 범위를 [0,1]에서 [-1,1] 범위 안으로 조정
- 데이터 1건이 [1,28,28]인 3계 텐서를 [784]인 1계 텐서로 변환
+ dataloader를 이용한 미니배치 학습법(그룹 단위로 경사 계산) -> 경사하강법의 local minimum 현상 해소
# 데이터 건수 확인
print('데이터 건수: ', len(train_set0))
# 첫번째 요소 가져오기
image, label = train_set0[0]
# 데이터 타입 확인
print('입력 데이터 타입 : ', type(image))
print('정답 데이터 타입 : ', type(label))
훈련용 데이터셋이 총 6만건임을 확인할 수 있다.
plt.figure(figsize=(10, 3))
for i in range(20):
ax = plt.subplot(2, 10, i + 1)
# image와 label 취득
image, label = train_set0[i]
# 이미지 출력
plt.imshow(image, cmap='gray_r')
ax.set_title(f'{label}')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
MNIST 클래스가 원본 데이터 파일을 감춘 채 파이썬으로 사용하기 간편한 리스트 형태의 인터페이스를 제공하고 있음을 알 수 있다.
데이터 전처리
import torchvision.transforms as transforms
transform1= transforms.Compose([transforms.ToTensor()])
train_set1= datasets.MNIST(root= data_root,train=True,download=True, transform= transform1)데이터를 텐서로 변환하고 이를 transform1이라는 새로운 인스턴스를 정의한다.
image, label = train_set1[0]
print('입력 데이터 타입 : ', type(image))
print('입력 데이터 shape : ', image.shape)
print('최솟값 : ', image.data.min())
print('최댓값 : ', image.data.max())
image 변수가 텐서로 변환되었다. 변환된 데이터의 shape은 [1,28,28]이고, 최솟값은 0, 최댓값은 1이다.
transform2 = transforms.Compose([
# 데이터를 텐서로 변환
transforms.ToTensor(),
# 데이터 정규화
transforms.Normalize(0.5, 0.5),
])
train_set2 = datasets.MNIST(
root = data_root, train = True, download = True,
transform = transform2)Normalize(평균, 표준편차) 로 X = (x-평균)/표준편차에 따라 변환된다. 여기서 평균과 표준편차를 모두 0.5로 설정하여 [-1,1] 사이의 값으로 변경하였다.
image, label = train_set2[0]
print('shape : ', image.shape)
print('최솟값 : ', image.data.min())
print('최댓값 : ', image.data.max())
최댓값과 최솟값을 보면 [-1,1]사이의 값으로 변환된 것을 알 수 있다.
transform3 = transforms.Compose([
# 데이터를 텐서로 변환
transforms.ToTensor(),
# 데이터 정규화
transforms.Normalize(0.5, 0.5),
# 현재 텐서를 1계 텐서로 변환
transforms.Lambda(lambda x: x.view(-1)),
])
train_set3 = datasets.MNIST(
root = data_root, train = True,
download=True, transform = transform3)fully connected layer에 입력하기 위해 입력 변수의 shape을 원본 [1,28,28]에서 [784]로 변경한다.
image, label = train_set3[0]
print('shape : ', image.shape)
print('최솟값 : ', image.data.min())
print('최댓값 : ', image.data.max())
원본 데이터의 shape이 [1,28,28]이 [784]로 치환되었다.
미니 배치 학습
from torch.utils.data import DataLoader
# 미니 배치 사이즈 지정
batch_size = 500
# 훈련용 데이터로더
# 훈련용이므로, 셔플을 적용함
train_loader = DataLoader(
train_set, batch_size = batch_size,
shuffle = True)
# 검증용 데이터로더
# 검증시에는 셔플을 필요로하지 않음
test_loader = DataLoader(
test_set, batch_size = batch_size,
shuffle = False)배치 사이즈와 shuffle을 파라미터로 지정해준다 . test 데이터에는 shuffle 지정을 False로 해준다.
# 몇 개의 그룹으로 데이터를 가져올 수 있는가
print(len(train_loader))
# 데이터로더로부터 가장 처음 한 세트를 가져옴
for images, labels in train_loader:
break
print(images.shape)
print(labels.shape)
train_loader의 길이가 120은 60000/500의 계산 결과이다. batche_size=500으로 지정한 사실과 같이 images는 [500,784], labels는 [500]으로 나타난다.
# 입력 차원수
n_input = image.shape[0]
# 출력 차원수
# 분류 클래스 수는 10
n_output = len(set(list(labels.data.numpy())))
# 은닉층의 노드 수
n_hidden = 128
# 결과 확인
print(f'n_input: {n_input} n_hidden: {n_hidden} n_output: {n_output}')
은닉층 노드 수를 포함하여 다음과 같은 결과가 나왔다.
class Net(nn.Module):
def __init__(self, n_input, n_output, n_hidden):
super().__init__()
# 은닉층 정의(은닉층 노드 수 : n_hidden)
self.l1 = nn.Linear(n_input, n_hidden)
# 출력층 정의
self.l2 = nn.Linear(n_hidden, n_output)
# ReLU 함수 정의
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x1 = self.l1(x)
x2 = self.relu(x1)
x3 = self.l2(x2)
return x3nn.Linear가 두개로 늘어났고, 활성화함수로 ReLU 함수를 적용하고 있다. 두번째 출력층 nn.Linear(n_hidden,n_output)에 대해서 활성화 함수가 없는 것은 손실함수 쪽에 softmax 함수를 포함할 예정이기 때문이다. 이전 구현과 다르게 파라미터의 초깃값을 모두 1.0으로 설정했던 부분이 없다는 것이다. 난수를 사용해여 초기값을 설정한다.
torch.manual_seed(123)
torch.cuda.manual_seed(123)
# 모델 인스턴스 생성
net = Net(n_input, n_output, n_hidden)
# 모델을 GPU로 전송
net = net.to(device)최적화 알고리즘과 손실함수를 정의해준다.
lr = 0.01
# 최적화 알고리즘: 경사 하강법
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
# 손실 함수: 교차 엔트로피 함수
criterion = nn.CrossEntropyLoss()for parameter in net.named_parameters():
print(parameter)
파라미터를 확인하면 위와 같이 나온다. l1.weight, l1.bias 뿐 아니라 l2.weight, l2.bias 까지 늘어났다.
print(net)
선형함수의 인스턴스가 두개로 늘어났고, ReLU 인스턴스가 생성되었다.
예측 계산
for images, labels in train_loader:
break
inputs = images.to(device)
labels = labels.to(device)데이터로더에서 취득한 학습데이터inputs와 labels를 GPU로 보낸다.
outputs = net(inputs)
print(outputs)
net 함수에 inputs을 넣어 예측값을 계산한다.
# 손실 계산
loss = criterion(outputs, labels)
# 손실값 가져오기
print(loss.item())
loss.backward()2.3259594440460205
w = net.to('cpu')
print(w.l1.weight.grad.numpy())
print(w.l1.bias.grad.numpy())
print(w.l2.weight.grad.numpy())
print(w.l2.bias.grad.numpy())
경사 계산 결과를 출력한다.
# 경사 하강법 적용
optimizer.step()
# 파라미터 값 출력
print(net.l1.weight)
print(net.l1.bias)
경사하강법을 작용해서 파라미터값을 수정한다.
# 난수 고정
torch.manual_seed(123)
torch.cuda.manual_seed(123)
torch.backends.cudnn.deterministic = True
torch.use_deterministic_algorithms = True
# 학습률
lr = 0.01
# 모델 초기화
net = Net(n_input, n_output, n_hidden).to(device)
# 손실 함수: 교차 엔트로피 함수
criterion = nn.CrossEntropyLoss()
# 최적화 함수: 경사 하강법
optimizer = optim.SGD(net.parameters(), lr=lr)
# 반복 횟수
num_epochs = 100
# 평가 결과 기록
history = np.zeros((0,5))# tqdm 라이브러리 임포트
from tqdm.notebook import tqdm
# 반복 계산 메인 루프
for epoch in range(num_epochs):
train_acc, train_loss = 0, 0
val_acc, val_loss = 0, 0
n_train, n_test = 0, 0
# 훈련 페이즈
for inputs, labels in tqdm(train_loader):
n_train += len(labels)
# GPU로 전송
inputs = inputs.to(device)
labels = labels.to(device)
# 경사 초기화
optimizer.zero_grad()
# 예측 계산
outputs = net(inputs)
# 손실 계산
loss = criterion(outputs, labels)
# 경사 계산
loss.backward()
# 파라미터 수정
optimizer.step()
# 예측 라벨 산출
predicted = torch.max(outputs, 1)[1]
# 손실과 정확도 계산
train_loss += loss.item()
train_acc += (predicted == labels).sum().item()
# 예측 페이즈
for inputs_test, labels_test in test_loader:
n_test += len(labels_test)
inputs_test = inputs_test.to(device)
labels_test = labels_test.to(device)
# 예측 계산
outputs_test = net(inputs_test)
# 손실 계산
loss_test = criterion(outputs_test, labels_test)
# 예측 라벨 산출
predicted_test = torch.max(outputs_test, 1)[1]
# 손실과 정확도 계산
val_loss += loss_test.item()
val_acc += (predicted_test == labels_test).sum().item()
# 평가 결과 산출, 기록
train_acc = train_acc / n_train
val_acc = val_acc / n_test
train_loss = train_loss * batch_size / n_train
val_loss = val_loss * batch_size / n_test
print (f'Epoch [{epoch+1}/{num_epochs}], loss: {train_loss:.5f} acc: {train_acc:.5f} val_loss: {val_loss:.5f}, val_acc: {val_acc:.5f}')
item = np.array([epoch+1 , train_loss, train_acc, val_loss, val_acc])
history = np.vstack((history, item))tqdm는 진행상황을 보여주는 프로그레스바가 출력된다.

print(f'초기상태 : 손실 : {history[0,3]:.5f} 정확도 : {history[0,4]:.5f}' )
print(f'최종상태 : 손실 : {history[-1,3]:.5f} 정확도 : {history[-1,4]:.5f}' )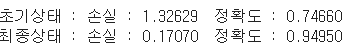
# 데이터로더에서 처음 한 세트 가져오기
for images, labels in test_loader:
break
# 예측 결과 가져오기
inputs = images.to(device)
labels = labels.to(device)
outputs = net(inputs)
predicted = torch.max(outputs, 1)[1]plt.figure(figsize=(10, 8))
for i in range(50):
ax = plt.subplot(5, 10, i + 1)
# 넘파이 배열로 변환
image = images[i]
label = labels[i]
pred = predicted[i]
if (pred == label):
c = 'k'
else:
c = 'b'
# 이미지의 범위를 [0, 1] 로 되돌림
image2 = (image + 1)/ 2
# 이미지 출력
plt.imshow(image2.reshape(28, 28),cmap='gray_r')
ax.set_title(f'{label}:{pred}', c=c)
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
정확도는 약 95% 정도로 나왔고, test 데이터를 통해 숫자 이미지의 인식 결과가 보여진다. 예측 결과가 틀린 사진은 객관적으로 알기 힘든 글씨이기 때문에 정확도가 꽤나 높은 모델이 만들어졌다고 볼 수 있다.
은닉층 추가
class Net2(nn.Module):
def __init__(self, n_input, n_output, n_hidden):
super().__init__()
# 첫번째 은닉층 정의(은닉층 노드 수: n_hidden)
self.l1 = nn.Linear(n_input, n_hidden)
# 두번째 은닉층 정의(은닉층 노드 수: n_hidden)
self.l2 = nn.Linear(n_hidden, n_hidden)
# 출력층 정의
self.l3 = nn.Linear(n_hidden, n_output)
# ReLU 함수 정의
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x1 = self.l1(x)
x2 = self.relu(x1)
x3 = self.l2(x2)
x4 = self.relu(x3)
x5 = self.l3(x4)
return x5위와 같이 nn.Linear를 하나더 추가하여 은닉층을 두개 포함한다. 활성화 함수도 은닉층 사이에 하나더 추가한다.
# 난수 고정
torch.manual_seed(123)
torch.cuda.manual_seed(123)
# 모델 초기화
net = Net2(n_input, n_output, n_hidden).to(device)
# 손실 함수: 교차 엔트로피 함수
criterion = nn.CrossEntropyLoss()
# 최적화 함수: 경사 하강법
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
print(net)
선형함수의 인스턴스 변수가 l1,l2,l3 세개로 늘어났음을 확인할 수 있다.
만약 활성화 함수를 시그모이드로 설정했을 때, 경사값이 0에 가깝게 되는것을 알 수 있다.
이것을 기울기 소실이라고 하며, 기울기 소실시 가중치 업데이트가 안되는 문제가 발생한다. 그래서 ReLU 함수는 입력값이 양이기만 하면 x값에 의존하지 않고 경사값은 항상 일정하다. 그러므로 경사소실이 일어나기 힘들다는 것이다.


배치 사이즈가 작을 수록 정확도가 높게 나옴을 알 수 있다. 미니배치 학습법에서 배치사이즈는 중요한 파라미터라는 점을 확인할 수 있다. 무조건적으로 배치사이즈를 작게 하기보다 여러배치를 적용해보면서 튜닝결과를 확인해보는 것이 좋다.
배치사이즈 튜닝도 성능향상에 큰 영향을 주는것을 명심하자.