다중분류 with pytorch
출처: 차근차근 실습하며 배우는 파이토치 딥러닝 프로그래밍
이진분류 예측은 정답은 1 or 0 이어서 '확률' (nn.sigmoid) 를 이용해 정답이 어느정도 가까운지 확인했었음.
다중분류에서는 입력값 -> 예측 모델 -> 확률값으로 나온 출력값 중 확률이 가장 큰 것을 고른다.
예를들어 00으로 나올확률의 출력이 0.8/ 01로 나올 확률의 출력 0.2 / 02로 나올 확률의 출력이 0.33/ 이면, 출력값이 가장 큰 예측값으로 00을 도출하는 것이다.
이진분류에서는 가중치와 입력벡터를 내적하고, bias를 더했지만
다중분류에서는 가중치 벡터와 입력벡터를 행렬곱 연산을 하고 bias를 더해준다.

다중분류에선 softmax 함수를 사용한다. softmax는 입력값이 가장크면 확률값도 가장 크도록 출력한다. 전체 확률값을 더하면 1이다.

다중분류의 손실함수는 교차 엔트로피 함수를 사용한다.

교차 엔트로피 함수는 softmax 함수 출력인 중간 텐서 x2에 안의 모든 요소들에 로그를 취한 다음 정답요소만을 골라낸다.
마지막 정답 요소 추출을 위해서는 정답이 (0,1,2) 중 어느것인지 반드시 정수값을 주어져야한다. 손실함수로 넘겨줄 정답(두번째 인수) 는 반드시 정수값으로 이루어져야한다.

본래 교차 엔트로피 함수는 로그함수+ NLLoss에 해다하는 부분이지만 파이토치에서는 softmax 까지 포함시킨다.
모델 구현은 다음과 같이 진행된다.
예측 함수 쪽에서는 activation function이 필요없고, nn.Linear 의 출력을 그대로 사용.
예측함수 출력으로부터 확률값 얻고 싶을 때 예측 함수 출력에 softmax 적용
손실함수는 cross entropy loss 적용
cross entropy 함수는 가장 끝단이 nn.NLLoss 함수이므로 두번째 인수에 들어갈 정답은 NLLoss 함수와 마찬가지로 정숫값일 필요가 있음
모델 구현 부분만 코드 작성함
n_input = x_train.shape[1]
n_output = len(list(set(y_train)))
print(f'n_input: {n_input} n_output: {n_output}')n_input: 2 n_output: 3
class Net(nn.Module):
def __init__(self,n_input,n_output):
super().__init__()
self.l1 = nn.Linear(n_input,n_output)
self.l1.weight.data.fill_(1.0)
self.l1.bias.data.fill_(1.0)
def forward(self,x):
x1= self.l1(x)
return x1
net = Net(n_input,n_output)활성화 함수 호출한 부분이 사라지고 단순히 선형함수 결과를 반환하고 있다. cross entropy loss쪽에서 softmax 함수까지 커버하고 있기 때문이다.
for parameter in net.named_parameters():
print(parameter)
파라미터를 확인해보면 weight는 3행 2열, bias는 3차원 벡터임을 알 수 있다.
criterion = nn.CrossEntropyLoss()
lr = 0.01
optimizer = optim.SGD(net.parameters(),lr = lr)nn.CrossEntropyLoss()는 softmax, log함수, 정답요소 추출까지 세가지를 모두 한번에 처리하는 함수이다.
inputs = torch.tensor(x_train).float()
labels = torch.tensor(y_train).long()
# 검증 데이터의 텐서 변수화
inputs_test = torch.tensor(x_test).float()
labels_test = torch.tensor(y_test).long()loss로 넘기는 값은 반드시 정수여야 하기 때문에 labels에는 float이 아닌 long을 사용한다.
계산 그래프를 보면 손실함수는 logsoftmax 와 NLLoss 로 이루어져 있다.


예측 라벨은 다음과 같이 얻는다.
softmax 함수 이전 상태에서 최댓값을 가지면, softmax 함수 이후에도 최대가 되는 성질을 가져서 그것이 예측 라벨이 된다.
outputs = net(inputs)
print(torch.max(outputs,1)) #행별 최댓값 집계
torch.max(outputs,1)[1]
[1]를 취해서 인덱스 값만을 얻는다.
# 학습률
lr = 0.01
# 초기화
net = Net(n_input, n_output)
# 손실 함수: 교차 엔트로피 함수
criterion = nn.CrossEntropyLoss()
# 최적화 함수: 경사 하강법
optimizer = optim.SGD(net.parameters(), lr=lr)
# 반복 횟수
num_epochs = 10000
# 평가 결과 기록
history = np.zeros((0,5))for epoch in range(num_epochs):
# 훈련 페이즈
# 경사 초기화
optimizer.zero_grad()
# 예측 계산
outputs = net(inputs)
# 손실 계산
loss = criterion(outputs, labels)
# 경사 계산
loss.backward()
# 파라미터 수정
optimizer.step()
# 예측 라벨 산출
predicted = torch.max(outputs, 1)[1]
# 손실과 정확도 계산
train_loss = loss.item()
train_acc = (predicted == labels).sum() / len(labels)
# 예측 페이즈
# 예측 계산
outputs_test = net(inputs_test)
# 손실 계산
loss_test = criterion(outputs_test, labels_test)
# 예측 라벨 산출
predicted_test = torch.max(outputs_test, 1)[1]
# 손실과 정확도 계산
val_loss = loss_test.item()
val_acc = (predicted_test == labels_test).sum() / len(labels_test)
if ((epoch) % 10 == 0):
print (f'Epoch [{epoch}/{num_epochs}], loss: {train_loss:.5f} acc: {train_acc:.5f} val_loss: {val_loss:.5f}, val_acc: {val_acc:.5f}')
item = np.array([epoch, train_loss, train_acc, val_loss, val_acc])
history = np.vstack((history, item))반복처리 후 학습결과는 다음과 같다.
print(f'초기상태 : 손실 : {history[0,3]:.5f} 정확도 : {history[0,4]:.5f}' )
print(f'최종상태 : 손실 : {history[-1,3]:.5f} 정확도 : {history[-1,4]:.5f}' )초기상태 : 손실 : 1.09263 정확도 : 0.26667
최종상태 : 손실 : 0.19795 정확도 : 0.96000
이전에 비해 손실이 많이 줄어들고 정확도가 많이 상승함을 알 수 있다.
모델 출력 확인
print(labels[[0,2,3]])tensor([1, 0, 2])
i3 = inputs[[0,2,3],:]
print(i3.data.numpy())
정답데이터의 인덱스에 해당하는 입력값을 추출해준다.
softmax = torch.nn.Softmax(dim=1)
o3 = net(i3)
k3 = softmax(o3)
print(o3.data.numpy())
print(k3.data.numpy())
i3의 인수로 net 함수를 호출하고, 그 결과를 o3에 대입한후, softmax 함수에 적용한다.
첫번째 행렬은 선형함수의 출력결과, 두번째 함수는 softmax함수에 적용한 결과이다.
# 가중치 행렬
print(net.l1.weight.data)
# 바이어스
print(net.l1.bias.data)최종 학습으로 얻은 가중치 행렬과 바이어스값은 다음과 같다.
# 가중치 행렬
print(net.l1.weight.data)
# 바이어스
print(net.l1.bias.data)
NLL Loss 함수
위의 다중분류 모델에서 교차 엔트로피 함수 수식을 아래와 같이 정래했다.

위의 식을 엄밀하게 다시 쓴다면 다음과 같이 표현한다.

M은 학습 데이터의 건수, (m)은 몇 건째의 학습데이터인지를 나타내는 인덱스이다.
간략한 버전의 수식은 최우 추정에서 도출한 로그 우도 함수로 값을 최대화 하는 것이 목적이다. 경사하강법은 최솟값을 구하는 알고리즘으로 우도값에 마이너스를 곱해 목적을 최솟값으로 바꾼다.
NLLoss 함수란 위의 수식 중 로그 계산 부분을 제외한 함수다. 알기 쉽게 다음과 같이 치환할 수 있다.
log(ypi^(m))-> zpi(m)
# 입력 변수 준비
# 더미 출력 데이터
outputs_np = np.array(range(1, 13)).reshape((4,3))
# 더미 정답 데이터
labels_np = np.array([0, 1, 2, 0])
# 텐서화
outputs_dummy = torch.tensor(outputs_np).float()
labels_dummy = torch.tensor(labels_np).long() #정수
# 결과 확인
print(outputs_dummy.data)
print(labels_dummy.data)
nllloss = nn.NLLLoss()
loss = nllloss(outputs_dummy, labels_dummy)
print(loss.item())-6.25
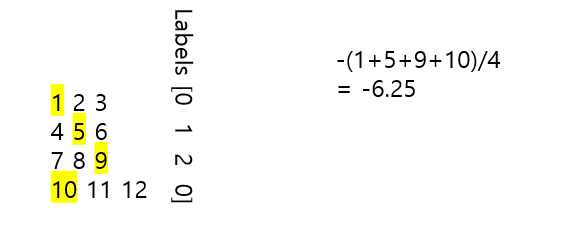
정답에 해당하는 요소만을 골라내서 평균값에 마이너스를 곱한 결과이다.