선형회귀 with Pytorch
출처: 차근차근 실습하며 배우는 파이토치 딥러닝 프로그래밍
선형 함수
다음 레이어 함수는 2차원의 입력을 받아 3차원 텐서로 출력하는 함수이다.
l3 = nn.Linear(2,3)
단일 회귀 함수는 다음과 같이 구현된다
1입력 1출력으로 표시되고 있고, bias(정수항)은 기본으로 True로 설정되어있다.
torch.manual_seed(123)
# 입력 :1 출력 :1 선형 함수의 정의
l1 = nn.Linear(1, 1)
# 선형 함수 확인
print(l1)Linear(in_features=1, out_features=1, bias=True)
for param in l1.named_parameters():
print('name: ', param[0])
print('tensor: ', param[1])
print('shape: ', param[1].shape)named_parameters()를 통해 어떤 파라미터를 포함하고 있는지 본다.

입출력 차원이 모두 1차원이므로, 원래 weight와 bias는 스칼라(0계텐서)여야 하지만, 입출력 텐서 차원수가 2이상으로 늘어났을 때를 대비해 확장하기 위해 [1,1] 행렬 [1] 벡터 형태를 띄운다. 레이어 함수안의 파라미터는 학습의 대상이므로 처음부터 자동적으로 requires_grad=True로 설정한다.
nn.init.constant_(l1.weight,2.0)
nn.init.constant_(l1.bias,1.0)
print(l1.weight)
print(l1.bias)
다음과 같이 파라미터 값을 nn.init.constant_값을 통해 직접설정할 수 있다. y = 2x+1을 정의하였다.
# 테스트용 데이터 생성
# x_np를 넘파이 배열로 정의
x_np = np.arange(-2, 2.1, 1)
# 텐서 변수화
x = torch.tensor(x_np).float()
# (N,1) 사이즈로 변경
x = x.view(-1,1)
# 결과 확인
print(x.shape)
print(x)
입력변수 x를 2차원 텐서로 변환하여 스칼라가 아닌 [1,1] 형태의 weight의 연산을 한다.
y= l1(x)
print(y.shape)
print(y.data)
위에서 출력한 x를 y = 2x+1에 입력값으로 넣어 출력한다. y의 shape 역시 [5,1]임을 알 수 있다.
다중회귀
다중회귀는 2입력 1출력 선형함수이다. 2입력은 wieght의 요소수가 2개임을 의미한다. y= x1+x2+2 다중회귀를 구현해보았다.
l2 = nn.Linear(2,1)
nn.init.constant_(l2.weight,1.0)
nn.init.constant_(l2.bias,2.0)
print(l2.weight)
print(l2.bias)
weight값은 1, bias는 2값을 입력하였다.
# 2차원 넘파이 배열
x2_np = np.array([[0, 0], [0, 1], [1, 0], [1,1]])
# 텐서 변수화
x2 = torch.tensor(x2_np).float()
# 결과 확인
print(x2.shape)
print(x2)
입력으로 들어갈 텐서를 입력한다. y= x1+x2+2에 [0,0] [0,1]을 대입했을 때 다음과 같이 출력된다.
y2= l2(x2)
print(y2.shape)
print(y2.data)
다중회귀 분석의 출력을 늘려서 2입력 3출력 으로 진행해보았다.
l3 = nn.Linear(2,3)
nn.init.constant_(l3.weight[0,:], 1.0)
nn.init.constant_(l3.weight[1,:], 2.0)
nn.init.constant_(l3.weight[2,:], 3.0)
nn.init.constant_(l3.bias, 2.0)
print(l3.weight)
print(l3.bias)
y3= l3(x2)
print(y3.shape)
print(y3.data)

class 를 이용한 모델 정의
class Net(nn.Module):
def __init__(self,n_input,n_output):
super().__init__() #부모 클래스 nn.Module 초기화
self.l1 = nn.Linear(n_input,n_output) #출력층 정의
def forward(self,x): #예측함수
x1= self.l1(x)
return x1inputs = torch.ones(100,1)
n_input = 1
n_output = 1
net = Net(n_input,n_output)
outputs = net(inputs)클래스 Net의 인스턴스 변수 net은 함수 그자체로 동작한다.
MSELoss 손실함수
손실을 파라미터로 편미분하는 것이 경사 계산이며, 경사 계산의 결과를 경사 하강법의 파라미터 수정에 사용한다.
criterion = nn.MSELoss()
outputs = net(inputs)
loss= criterion(outputs,labels1)/2.0
loss.backward() #경사 계산criterion을 nn.MSELoss 클래스의 인스턴스로 정의한다. MSE는 평균제곱오차(Mean square Loss) 이다.
여기서도 인스턴스 변수 criterion을 함수로 이용하고 있다. backward를 통해 loss 계산의 경사 계산이 이루어진다.
회귀 / MSELoss/ 평균오차
이진분류 / BCELoss/ 이진 분류용 교차 엔트로피 함수
다중분류 / CrossEntropyLoss/ 다중분류용 교차 엔트로피 함수
데이터셋 적용
보스턴 하우스 데이터셋을 적용하여 모델을 구현해보았다.
n_input = x.shape[1]
n_output = 1
print(f'입력 차원수: {n_input} 출력 차원수: {n_output}')입력 차원수: 1 출력 차원수: 1
class Net(nn.Module):
def __init__(self,n_input,n_output):
super().__init__() #부모 클래스 nn.Module 초기화
self.l1 = nn.Linear(n_input,n_output)
nn.init.constant_(self.l1.weight, 1.0)
nn.init.constant_(self.l1.bias, 1.0)
def forward(self,x): #예측함수 정의
x1= self.l1(x) #선형회귀
return x1가중치와 편향을 모두 1로 초기값을 설정해서 Net 클래스를 정의했다.차원 역시 nn.Linear(1,1) 이므로 l1.weight는 shape = [1,1]인 2계 텐서, l1.bias 는 shape=[1]인 1계 텐서이다.
파이토치 에서는 클래스 내부에 forward함수를 정의해서 inputs을 받아 outputs을 반환하기 위한 처리를 기술한다.
net = Net(n_input,n_output)
outputs = net(inputs)class Net의 인스턴스 변수 net을 생성한다.
for parameter in net.named_parameters():
print(f'변수명: {parameter[0]}')
print(f'변숫값: {parameter[1].data}')
net 변수안의 파라미터를 확인한다. 가중치는 2계텐서, 편향은 1계텐서로 값은 모두 1로 되어있다.
criterion = nn.MSELoss() #loss function
lr = 0.01 #학습률
optimizer = optim.SGD(net.parameters(),lr=lr) #최적화손실함수와 최적화를 진행한다.
inputs = torch.tensor(x).float()
labels = torch.tensor(yt).float()
print(inputs.shape)
print(labels.shape)torch.Size([506, 1])
torch.Size([506])
입력값 x와 정답 yt를 텐서 변수화 한다.
labels1 = labels.view((-1, 1))
print(labels1.shape)torch.Size([506, 1])
labels1 = labels.view((-1, 1))
print(labels1.shape)torch.Size([506, 1])
텐서로 변환한 정답 labels는 criterion 함수로 예측값과 함께 넘겨주고 손실을 계산한다. 인수는 N차원 벡터 형식이 아니라 (N,1) 차원 행렬 형식을 만족해야하기 때문에 view함수를 이용해 데이터 사이즈를 변경한다.
# 예측 계산
outputs = net(inputs)
# 손실 계산
loss = criterion(outputs, labels1)
# 경사 계산
loss.backward()
# 경사 계산 결과를 취득 가능하도록 함
print(net.l1.weight.grad)
print(net.l1.bias.grad)tensor([[-199.6421]])
tensor([-30.4963])
파라미터 수정은 step을 사용한다. 파라미터 수정은 w= w- lr* grad 으로 이루어진다.
# 파라미터 수정
optimizer.step()
# 파라미터 확인
print(net.l1.weight)
print(net.l1.bias)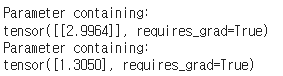
초기값 1.0과 다른값으로 수정되었다. 이후 경사값을 초기화 하여 경사값이 누적되어 더해지는것을 피한다.
# 경삿값 초기화
optimizer.zero_grad()
print(net.l1.weight.grad)
print(net.l1.bias.grad)
반복 계산을 통해 에폭이 100번째 일때마다 손실값을 기록한다.
lr = 0.01
net = Net(n_input,n_output)
criterion = nn.MSELoss()
optimizer = optim.SGD(net.parameters(),lr = lr)
num_epochs = 5000
history = np.zeros((0,2))
# 반복 계산 메인 루프
for epoch in range(num_epochs):
# 경삿값 초기화
optimizer.zero_grad()
# 예측 계산
outputs = net(inputs)
# 손실 계산
loss = criterion(outputs, labels1) / 2.0
# 경사 계산
loss.backward()
# 파라미터 수정
optimizer.step()
# 100회 마다 도중 경과를 기록
if ( epoch % 100 == 0):
history = np.vstack((history, np.array([epoch, loss.item()])))
print(f'Epoch {epoch} loss: {loss.item():.5f}')print(f'초기 손실값: {history[0,1]:.5f}')
print(f'최종 손실값: {history[-1,1]:.5f}')초기 손실값: 154.22493
최종 손실값: 24.26480
손실값이 초기에 비해 개선된 것을 알 수 있다.