Deep Learning/NLP
07. TF-IDF(단어빈도-역문서빈도)
해파리냉채무침
2023. 3. 18. 16:27
단어빈도- 역문서 빈도
tfidf(t,d,D) = tf(t,d) * idf(t,D)
tf(d,t) -한문서 안에서 단어가 많이 등장할수록 가중치가 높아짐.
df(t) -특정 단어 t가 등장한 문서의 수
idf(d,t)- df(t)의 역수
TF-IDF가 높은 것 -> 특정 문서에 많이 등장하고 타 문서에 많이 등장하지 않는 단어
문서 1 : The cat sat on my face I hate a cat
문서 2: The dog sat on my bed I love a dog
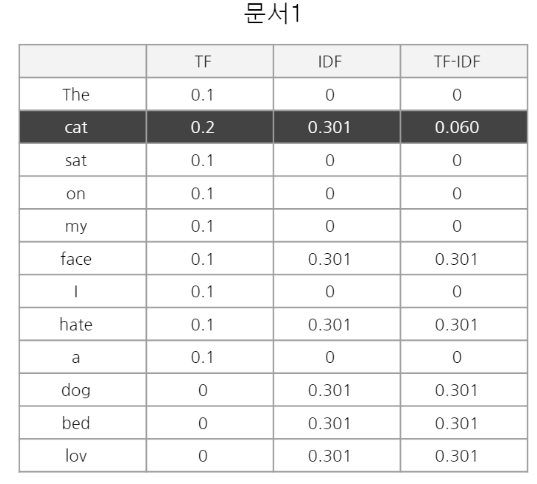
문서 1의 벡터는 (0,0.06,0,0,0,0.301,0,0.301,0,0.301,0.301,0.301)이 된다.
TF-IDF을 통해 문서간의 유사도를 측정할때 더 좋은 성능을 낼 수 있다. 질의에 대한 tfidf 벡터와 문서의 tfidf 벡터를 가지고 비교해서 유사도가 높은 것을 상위에 보여주는 것으로 질의응답 시스템이 구축되어 있음.
단어 문맥행렬 -> 유사한의미를 가지거나 관련있는 단어들이 보일때 사용
code
d1 = "The cat sat on my face I hate a cat"
d2 = "The dog sat on my bed I love a dog"
doc_ls = [d1, d2]
import numpy as np
from collections import defaultdict
def tf(t, d) :
return d.count(t) / len(d)
def idf (t, D) :
N = len(D)
n = len([True for d in D if t in d])
return np.log(N/n)
def tfidf (t,d,D) :
return tf(t,d) * idf(t,D)
def tokenizer(d) :
return d.split()
def tfidfScorer(D) :
doc_ls = [tokenizer(d) for d in D]
word2id = defaultdict(lambda:len(word2id))
[word2id[t] for d in doc_ls for t in d]
tfidf_mat = np.zeros((len(doc_ls), len(word2id)))
for i, d in enumerate(doc_ls) :
for t in d :
tfidf_mat[i, word2id[t]] = tfidf(t, d, D)
return tfidf_mat, word2id.keys()tfidfScorer(doc_ls)(array([[0. , 0.13862944, 0. , 0. , 0. ,
0.06931472, 0. , 0.06931472, 0. , 0. ,
0. , 0. ],
[0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 0. , 0.13862944,
0.06931472, 0.06931472]]),
dict_keys(['The', 'cat', 'sat', 'on', 'my', 'face', 'I', 'hate', 'a', 'dog', 'bed', 'love']))mat, vocab = tfidfScorer(doc_ls)
import pandas as pd
pd.DataFrame(mat,columns=vocab)The cat sat on my face I hate a dog bed love
| 0.0 | 0.138629 | 0.0 | 0.0 | 0.0 | 0.069315 | 0.0 | 0.069315 | 0.0 | 0.000000 | 0.000000 | 0.000000 |
| 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.0 | 0.138629 | 0.069315 | 0.069315 |
sklearn
d1 = "The cat sat on my face I hate a cat"
d2 = "The dog sat on my bed I love a dog"
docs = [d1, d2]
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vect = TfidfVectorizer()
tfidf = tfidf_vect.fit_transform(docs)
tfidf.todense()matrix([[0. , 0.70600557, 0. , 0.35300279, 0.35300279,
0. , 0.25116439, 0.25116439, 0.25116439, 0.25116439],
[0.35300279, 0. , 0.70600557, 0. , 0. ,
0.35300279, 0.25116439, 0.25116439, 0.25116439, 0.25116439]])